按需付费 - AI Model Orchestration and Workflows Platform

AI workflows in 2026 face challenges like fragmented tools, unchecked model drift, and escalating costs. To overcome these, organizations are adopting smarter, automated workflows that unify tools, improve governance, and optimize spending. Here’s how you can transform your AI operations:
这些实践简化了工作流程、加强了监督并降低了成本,使组织能够负责任且高效地扩展人工智能。
__XLATE_1__
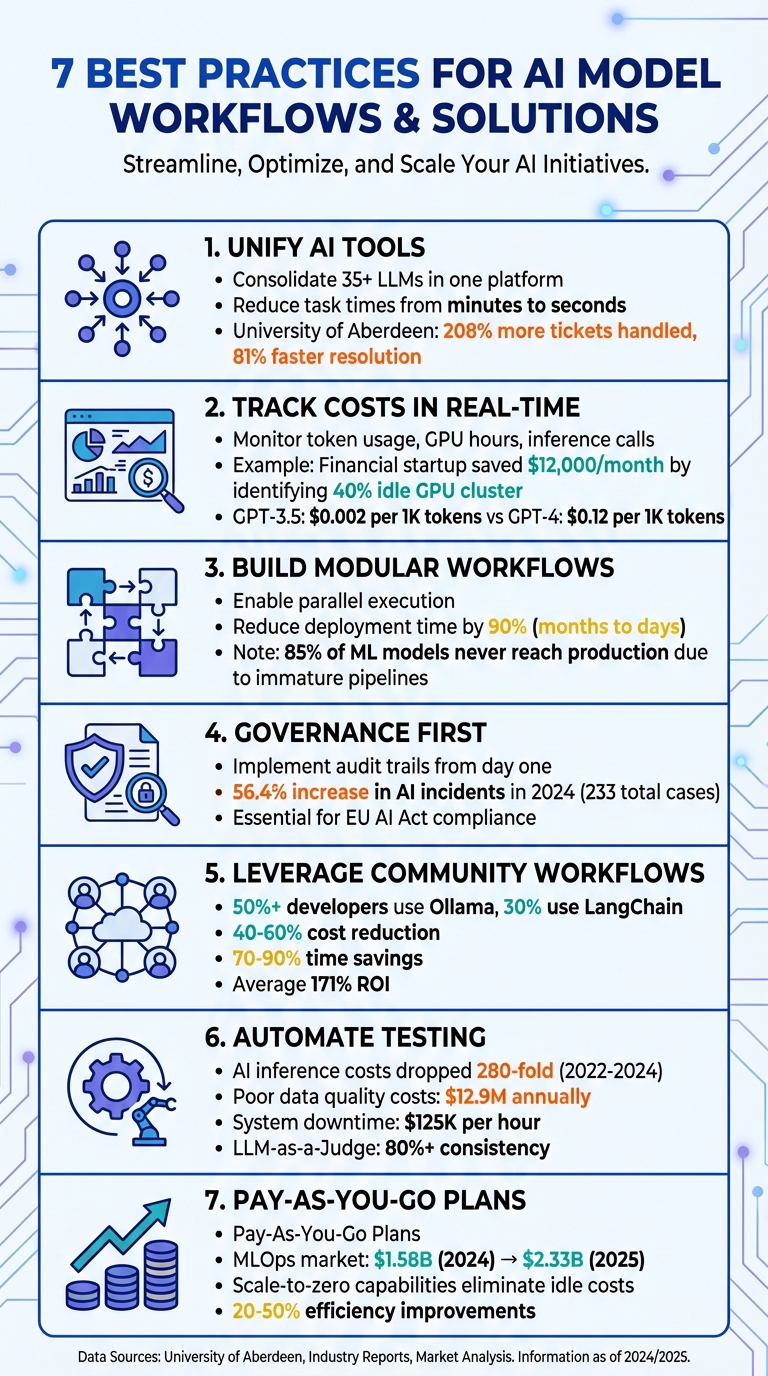
管理 GPT-5、Claude、LLaMA 和 Gemini 等模型的单独平台可能会减慢操作速度并造成不必要的障碍。通过将超过 35 个 LLM 整合到一个界面中,Prompts.ai 消除了处理多个登录和凭据的麻烦,将任务时间从几分钟缩短到仅仅几秒钟。
这种集成可以显着提高生产力。例如,当阿伯丁大学于 2025 年 9 月采用人工智能驱动的系统时,他们的 IT 团队成功处理了 208% 的罚单,同时将解决时间缩短了 81% [1]。这样的结果凸显了简化的系统如何让团队专注于结果,而不是浪费时间管理分散的工具。这种方法为更高效、更可靠、更经济高效的人工智能工作流程铺平了道路。
统一的界面不仅可以节省时间,还可以确保更高的可靠性和灵活性。通过从单一平台访问所有模型,团队可以在引擎之间无缝切换,即使一个模型失败或提供不准确的结果也能保持连续性。这种主动设置可以防止失控的流程,当自动化代理在没有适当控制的情况下循环时,失控的流程可能会导致云成本飙升。
该平台还支持并行性能测试,因此您可以评估哪种模型最适合特定任务。例如,客户支持查询可能会路由到一个法学硕士,创意项目路由到另一个,数据处理路由到第三个——所有这些都通过同一个仪表板进行管理。这种与模型无关的设计可确保您不受单个供应商的限制或定价的束缚,从而使您可以自由地优化性能和成本。
Prompts.ai 通过提供对所有模型中代币使用情况的实时洞察,将成本管理提升到一个新的水平。这种透明度有助于防止预算超支发生。内置的 FinOps 层可即时跟踪支出,从而更轻松地识别哪些工作流程提供价值以及哪些工作流程消耗资源。使用人工智能工作流程自动化的组织报告称,当他们可以将支出与业务成果联系起来时,他们的投资回报率高达 84%。例如,Databricks 通过由干净数据模型和透明成本跟踪支持的智能分类,将支持请求减少了 23% [1]。
该平台的即用即付 TOKN 积分使费用与实际使用情况保持一致,无需为未使用的容量付费。通过整合多个模型的成本,与为每个工具维护单独的订阅相比,团队可以节省高达 98% 的成本,从而在项目和部门之间节省大量成本。
Prompts.ai 还加强治理和合规性,提供统一的审计跟踪,支持监管要求和工作流程改进。该平台将任务分为风险级别,确保高风险操作(例如具有灾难性潜力的 4 级任务)始终处于人工监督之下,直到人工智能系统完全可靠。
通过端到端加密和严格的访问控制,敏感数据可以免受错误配置或破坏。由于 78% 的组织现在至少在其业务的一个领域使用 AI [2],Prompts.ai 提供企业级安全性,同时保持团队创新所需的速度和敏捷性。每次交互都是安全、可追踪和可审计的,让组织有信心负责任地扩展人工智能。
人工智能工作负载通常会导致不可预测的费用,而这些费用无法通过月度发票完全了解。实时 FinOps 通过在成本发生时提供即时洞察来改变这一现状。通过近乎实时地跟踪令牌使用情况、GPU 时间和推理调用,团队可以在预算超支失控之前识别并解决问题。
例如,一家金融分析初创公司发现其 8-GPU 集群中有 40% 闲置,每月浪费近 12,000 美元。通过实时监控,团队在冲刺中期发现了这种低效率的情况,并立即进行调整以优化容量。
按团队、项目或客户进行的精细跟踪进一步完善了退款模型。通过将客户 ID 等元数据附加到 API 请求,支出变得更加透明。这使得各部门只需为他们使用的资源付费,为可扩展且经济高效的运营铺平了道路。
Real-time tracking doesn’t just monitor costs - it actively supports smarter scaling decisions. Autoscaling can now factor in both performance metrics (like latency) and financial data (such as cost per prediction). For example, during traffic spikes, systems can throttle or reroute requests based on cost signals, ensuring resources are used efficiently.
__XLATE_13__
StreamForge AI 于 2025 年 9 月采用了这一策略,将 Kubecost 与 Prometheus 集成,并在 Grafana 仪表板上显示每五分钟刷新一次的利用率数据。使用双信号自动缩放方法(平衡 p95 延迟和每次请求成本指标),他们显着提高了 GPU 利用率,并提高了 300 多个日常训练作业的成本效益。这种实时方法有助于避免可能耗尽每月预算的代价高昂的错误配置。
Centralizing cost tracking across multiple AI providers is essential when managing diverse models. A unified AI gateway simplifies this process by consolidating token usage, latency, and cost data into a single, reliable source. Whether you’re using OpenAI, Anthropic, or self-hosted models, this centralized system eliminates the need to piece together fragmented billing data.
这种集成度至关重要,因为不同的型号具有截然不同的价格点。例如,GPT-3.5-Turbo 每 1,000 个代币的成本约为 0.002 美元,而 GPT-4 的成本可能高达每 1,000 个代币 0.12 美元,具体取决于上下文窗口。实时跟踪允许团队比较这些成本并将任务路由到最经济的模型。无论是处理简单的客户查询还是复杂的分析,任务都会根据实时成本数据分配给正确的模型,确保工作流程保持高效且预算友好。
将人工智能工作流程分解为模块化组件彻底改变了它们的部署和扩展方式。模块化方法不再依赖单一的、刚性的管道来处理每个阶段,而是允许更新或更换各个部件,而不会破坏整个系统。
这种设计还支持并行执行,多个任务可以同时运行。例如,多语言翻译服务可以同时处理各种语言版本,而不是一个接一个地处理,从而显着缩短处理时间。采用 MLOps 实践可进一步加速部署,将模型投入生产的时间缩短高达 90%。自动化管道可以将部署时间从几个月缩短到几天。
另一个优点是可重玩性。如果特定步骤(例如后处理)遇到问题,您可以使用存储的工件重新运行该模块,而不用重做整个工作流程。这种有针对性的重新运行方法可以节省时间和资源,特别是对于需要大量计算能力的任务。模块化工作流程还可以更轻松地标准化和安全地集成整个系统的组件。
一旦模块化基础就位,确保组件之间的顺畅通信就变得至关重要。标准化输入和输出格式有助于避免级联错误。例如,如果数据摄取模块输出一个明确定义的 JSON 文件,该文件与推理模块的预期输入完全一致,则可以消除潜在的误传。
将AI逻辑与策略逻辑分离进一步增强了可维护性。这使您能够独立于固定业务规则来管理动态模型行为,如 AWS 规范指南中所强调的那样。 Docker 或 Kubernetes 等工具可以对模块进行容器化,确保它们在不同环境中保持可移植性。容器化模块可以在开发、预演和生产中一致运行,甚至可以在云提供商之间进行转换,而无需进行更改。对于编排,AWS Step Functions 提供带有内置重试功能的无服务器协调,而 Apache Airflow 则提供基于 Python 的灵活性,用于管理更复杂的工作流程。
模块化设计还可以让您为每项任务分配正确的资源,从而带来经济效益。资源密集型的复杂推理模型可以保留用于要求较高的分析,而较简单的任务则由较便宜的模型处理。这确保了计算资源得到明智的使用。
在模块级别跟踪元数据可以提高透明度。通过在每个工件通过管道时附加时间戳、模型版本和成本数据等详细信息,团队可以获得清晰的审计跟踪。这不仅有助于调试,还有助于财务跟踪。将成本与特定于模块的指标相结合,可以在保持灵活性的同时进行精确的预算。此外,设置批量大小和并发性限制有助于防止高需求期间的意外支出。
It’s worth noting that about 85% of machine-learning models never make it to production, often due to immature pipeline structures. Modular, iterative workflows offer a way to overcome this challenge. Teams can start small, validate one module at a time, and gradually scale up, reducing risks and ensuring systems are ready for production.
从一开始就将治理纳入您的人工智能工作流程,可以让您免于进行成本高昂的调整。通过建立前面讨论的自动化评估和透明度,您可以确保从一开始就将合规性融入您的流程中。一旦创建了模型或用例, 在您的工作流程工具中生成跟踪单 并指定初始风险级别。与内部使用的低风险工具相比,信用评分或招聘系统等高风险应用程序需要更严格的审批流程和更密切的监控。这种主动的“左移”方法让您为监管要求做好准备,特别是像欧盟人工智能法案这样的框架,要求详细记录培训和评估流程。
合规的基石是 血统追踪,它提供了从原始数据到最终模型输出的清晰且可重复的路径。将谱系追踪与 快照追溯,确保在部署之前保留代码、数据和配置的确切状态。这允许您根据需要重现任何模型版本。行业研究强调了这些措施的紧迫性,指出 2024 年人工智能相关事件将增加 56.4%,总计 233 起,这强调了强有力的审计追踪的必要性。
审计跟踪通过直接将错误与其根源联系起来简化故障排除。工程师可以使用沿袭跟踪来快速识别管道中断或数据质量下降的位置,而不是手动筛选日志。自动化治理任务(例如资产检查和风险评估)不仅可以确保合规性,还可以让您的人工智能计划随着其发展而高效推进。通过自动化这些步骤,您可以减少审批时间并保持操作的一致性。
强大的数据治理对于维护高质量数据至关重要。集中元数据管理将所有人工智能资产的信息整合到一处,消除冗余并确保平稳运行。当每个组件(从提示到模型版本)都通过时间戳和成本详细信息进行跟踪时,团队将获得 全面的执行历史记录。这使得管道更容易复制和细化。自动审核日志进一步减少人为错误,建立可靠且可重复的工作流程。
这些治理策略与模块化工作流程无缝集成,确保合规性在系统扩展时仍然是系统的核心部分。
统一的治理层将简化的工作流程和成本透明度联系在一起,确保全面合规。许多系统(例如 Snowflake、Databricks、云平台和边缘环境)可以跨多个平台运行。如果没有统一的治理方法,您将面临“影子人工智能”的风险,即在没有监督的情况下部署模型,从而无法进行合规性验证。 跨系统追溯 确保跨查询、笔记本、作业和仪表板捕获运行时数据沿袭,从而在数据在平台之间移动时保持合规性。标准化接口,例如具有集中式网关的模型上下文协议 (MCP),可以实现跨服务器和租户的一致日志记录和请求跟踪。无论工作在哪里进行,这都可以为您提供完整的审计跟踪。
从头开始创建工作流程可能既耗时又低效。社区驱动的框架,例如 浪链 和 奥拉马 已成为首选解决方案,提供用于链接提示和集成工具的预构建模板。这些框架被广泛采用,超过 50% 的开发者使用 Ollama,近三分之一的开发者依赖 LangChain 来管理 AI 代理。它们用独立运行的灵活、无服务器功能取代了脆弱的自定义代码,使它们更易于管理和扩展。
关键的好处是 可扩展性且不复杂。通过依靠社区测试的模式,您可以切换模型(例如从 GPT 迁移到 Amazon Bedrock),而无需彻底修改您的编排逻辑。这种灵活性可以加快部署速度,同时保持一致性。研究表明,虽然编排是许多组织的首要任务,但只有少数组织完全实施了它。社区工作流程提供了实用的解决方案,可实现跨各种人工智能平台的无缝集成。
社区工作流程还解决了跨平台集成人工智能工具的挑战。标准如 模型上下文协议 (MCP) 解决平台蔓延的问题,这是一个令人担忧的问题 63% 的高管。这些协议允许人工智能代理和工具跨 Gmail、Slack 和 CRM 等平台协同工作,而无需手动输入数据。例如,一个简单的自然语言请求——例如“总结来自 Gmail 的最后 10 封电子邮件”。 - 可以通过预配置的 API 连接触发结构化任务。
__XLATE_52__
互操作性至关重要, 87% 的 IT 领导者 认为它对于采用人工智能驱动的系统至关重要。社区工作流程在设计时考虑到了弹性,提供自动重试、超时和并行执行等功能来处理潜在的模型故障。这些保障措施至关重要,特别是因为 87% 的开发者担心 AI 准确性, 和 81% 的人担心安全和隐私。除了改进集成之外,这些工作流程还有助于显着降低成本。
使用社区模板将自然语言提示转换为自动化工作流程可以大幅降低成本并节省时间。组织报告 成本降低 40-60% 和 节省 70-90% 的时间 当他们通过这些工作流程采用人工智能自动化时。从经过测试的解决方案开始,无需进行昂贵的试错过程。
这些工作流程还通过纳入标准化审计跟踪和元数据跟踪来提高透明度。它们自动记录数据源、权限和代理决策历史等详细信息。许多包括 人在回路 对敏感或高成本任务进行手动审查的检查点,确保在最重要的地方进行监督。通过在扩展期间管理推理成本,公司已经看到了平均 171% 投资回报率 利用社区构建的工作流程时。
自动化测试和评估是创建无缝人工智能生命周期的最后一部分。它消除了手动测试造成的延迟,手动测试通常会阻止模型投入生产 - 85% 的模型由于流程效率低下而无法部署。通过利用自动化 CI/CD/CT(持续培训)管道,部署时间从几个月缩短到几天。当性能指标低于设定阈值或有新数据可用时,这些管道可以自动重新训练模型,从而无需持续的手动监督。
经济效益是显而易见的。 2022 年至 2024 年间,人工智能推理成本下降了 280 倍,使得持续监控和再培训成为一种实用的选择。自动化管道还有助于及早发现问题,避免代价高昂的错误。例如,糟糕的数据质量每年会给公司造成 1,290 万美元的损失,而计划外的系统停机每小时可能造成 125,000 美元的损失。自动化数据验证步骤(例如识别架构不匹配、空值或分布变化)可确保问题在摄取阶段得到解决,从而防止出现更大的问题。
自动化不仅加快了工作流程,还减少了不必要的开支。自调整管道确保仅在必要时进行重新训练,从而减少空闲期间昂贵的 GPU 资源的使用。 LLM-as-a-Judge 等工具简化了评估流程,降低了成本,同时在数千次测试中保持了 80% 以上的一致性。
测试策略可以进一步优化预算。使用 Dev Proxy 等工具模拟测试可以让您对端点进行压力测试,而无需支付每次调用费用。从较小的模型和代表性数据集开始有助于在进行全面评估之前验证想法。此外,按项目、团队或模型版本标记云资源可以提供详细的计费见解,从而更轻松地决定哪些工作流程值得投资。
自动化测试还通过创建监管机构所需的审计跟踪来加强治理。治理门可确保工作流程暂停,直到关键资产(例如架构和基线数据)得到验证。每个模型快照都会经过标准的风险评估,结果会自动记录,并发出故障触发的票据以进行跟踪。
自动化可以监控三种主要类型的漂移: 数据漂移 (输入分布的变化), 性能漂移 (准确性下降或响应时间变慢),以及 安全漂移 (增加毒性或敏感信息的暴露)。警报会尽早标记这些问题,防止它们影响最终用户。此外,终止开关允许团队在事件期间快速禁用有问题的模型路由或功能,展示了一种实际的治理方法,可确保系统在最重要的时候保持受控。
即用即付计划是管理人工智能费用的明智方式,同时使团队能够轻松成长和适应。这些计划建立在成本跟踪和模块化可扩展性等策略的基础上,以确保资源得到有效利用。
With pay-as-you-go pricing, you’re only charged for the tokens and compute time you actually use. Real-time dashboards provide insights into token consumption, latencies, and outcomes, helping to pinpoint inefficiencies and eliminate unnecessary spending. When combined with scale-to-zero capabilities, this model becomes even more effective - idle inference endpoints automatically shut down, so you’re not paying for unused GPU resources.
For tasks that aren’t time-sensitive, such as exploratory data analysis or offline model training, spot pricing offers a lower-cost alternative to on-demand rates. These savings add up, especially when paired with tools that track usage and performance in real time, allowing teams to fine-tune their compute needs and stay within budget.
Elastic compute ensures that your workflows can adapt to changing demands without manual adjustments. Features like autoscaling node pools and serverless architectures handle fluctuating workloads seamlessly, so there’s no need to overprovision resources for peak usage. By separating model artifacts from application code and using cloud storage, pods can start up almost instantly, making scaling operations faster and more efficient.
This approach is particularly valuable when transitioning from pilot projects to full-scale production. As the global MLOps market grows - expected to rise from $1.58 billion in 2024 to $2.33 billion by 2025 - organizations need scalable systems that won’t require constant rebuilding. Pay-as-you-go plans align costs with actual usage, making it easier to expand models, users, or teams without driving up expenses.
即用即付计划与先进的团队工具携手合作,以简化成本管理和运营工作流程。现代工具将治理、审计跟踪和单点登录 (SSO) 和基于角色的访问控制 (RBAC) 等安全功能直接集成到编排层中。这些功能对于满足 SOC 2 或 ISO 27001 等合规性要求至关重要。
支持 OpenAI 兼容 API 的平台允许团队在 LLM 提供商或模型之间切换,而无需彻底修改其工作流程,从而确保新技术出现时的灵活性。托管环境通过整合权限、SLA、集中元数据跟踪和授权控制等功能,进一步增强团队运营。这些系统不仅可以与您的组织一起扩展,还可以保持满足监管标准所需的透明度和控制,确保每个团队成员都拥有正确的访问权限,并且记录每个操作以供审核。
构建有效的人工智能工作流程需要强大的模型与结构化和可扩展的方法相结合。前面讨论的七种实践有助于将脱节的人工智能计划转变为简化的、企业就绪的流程。通过整合不同的法学硕士、保持持续的成本监控以及利用模块化设计,您可以消除瓶颈并创建根据您的需求而发展的工作流程。从治理开始,确保每个人工智能决策既可追溯又合规,而社区驱动的提示和自动化测试周期可在不影响质量的情况下加快开发速度。这些策略构成了高效、可靠的人工智能操作的支柱。
如前所述,这些方法可以将入职和事件管理等工作流程的效率提高 20% 到 50%。实时成本跟踪与即用即付模式相结合,使费用与使用情况保持一致,避免预算超支,同时支持无缝扩展。通过集成自动化和反馈循环,人工智能系统可以自我优化、识别异常、提出改进建议并自主管理复杂任务。
向集成治理和自适应架构的转变强调了在坚实的基础上构建工作流程的重要性。标准化工具、清晰的组件边界和详细的跟踪可确保您的系统在新模型和功能出现时保持灵活性。通过专注于可扩展、可重复的流程,您可以从试点项目过渡到大规模生产,而无需不断检修。
这些策略共同将分散的实验转变为高效、负责且具有成本意识的工作流程。 准备好控制您的 AI 工作流程了吗? 借助 Prompts.ai,您可以轻松保护模型、管理成本并进行扩展。访问超过 35 个顶级模型、利用内置 FinOps 控件并实施企业级治理 - 所有这些都在一个界面中完成。 Prompts.ai 消除了工具蔓延、确保合规性,并让您的团队专注于创新,将 AI 混乱转变为精简、投资回报率驱动的运营。
要选择最合适的大型语言模型 (LLM),首先要清楚地确定您的具体需求 - 无论是写作、编码、客户支持还是其他应用程序。使用考虑性能、成本和隐私等因素的结构化方法评估模型。对于风险最小的任务,优先考虑更快、更经济的模型。另一方面,高风险任务需要更可靠并包含适当监督的模型。基准测试是确保所选模型满足您的任务要求和运营目标的关键步骤。
为了控制人工智能成本,必须进行监控 代币使用 正如它所发生的那样。这涉及跟踪请求、提示和模型调用。通过掌握这些指标,您可以发现效率低下的地方并进行调整以优化资源使用,从而保持成本和性能之间的平衡。
为了领先于模型漂移,请建立自动监控系统,实时密切关注性能指标和数据质量。这些工具可以通过检查数据分布和预测准确性的变化来发现概念漂移、协变量漂移或标签漂移等变化。当检测到漂移时,预定义的重新训练触发器可以快速更新您的模型,从而在 MLOps 流程中保持一致的验证和平滑的集成。



















