Pague Conforme o Uso - AI Model Orchestration and Workflows Platform

Grandes Modelos de Linguagem (LLMs) são poderosos, mas imprevisíveis, muitas vezes produzindo resultados inconsistentes ou dispendiosos. Para enfrentar estes desafios, as organizações contam com ferramentas especializadas para avaliação, monitoramento e gestão de custos. Este artigo apresenta cinco plataformas que agilizam a análise de resultados do LLM:
Cada plataforma aborda aspectos exclusivos dos fluxos de trabalho LLM, desde melhorar a precisão até reduzir custos e garantir conformidade.
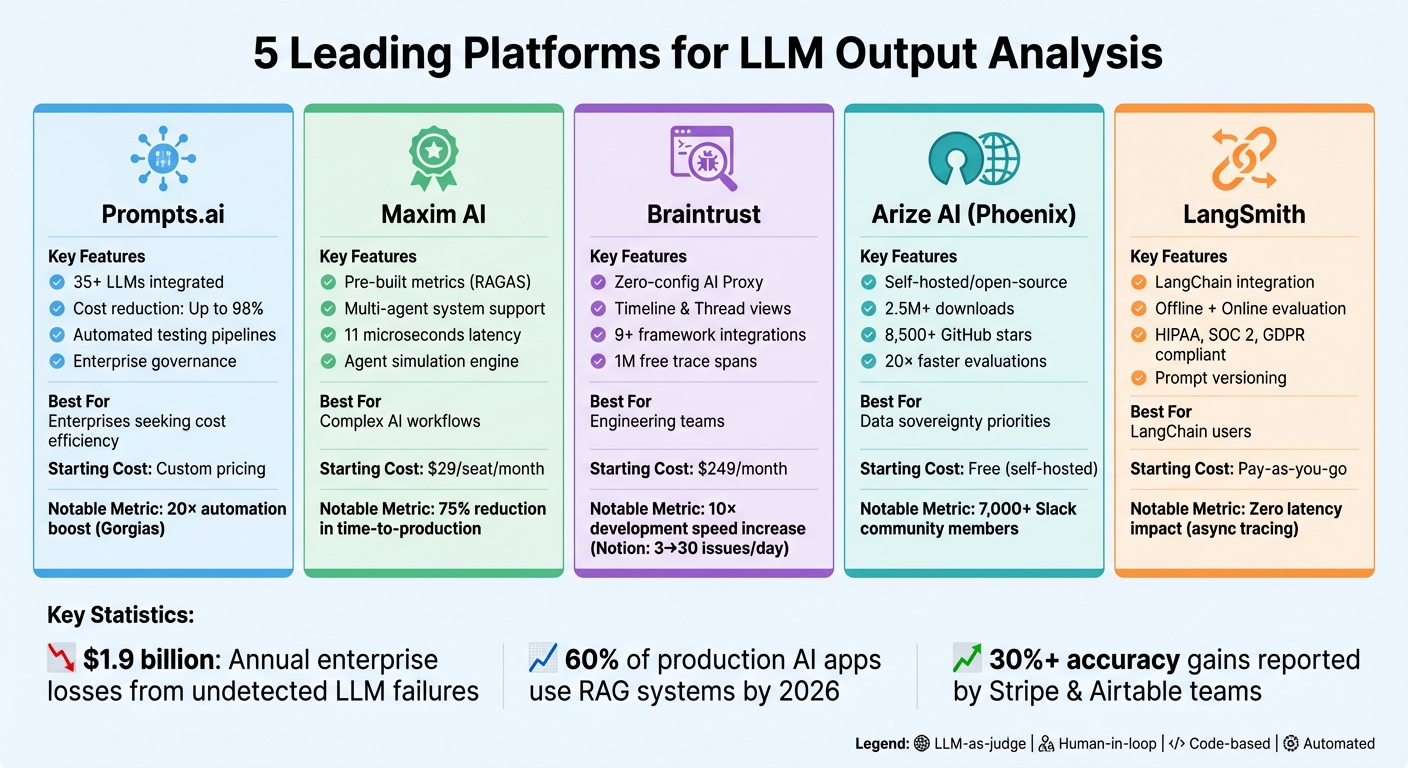
| Plataforma | Principais recursos | Melhor para | Custo inicial |
|---|---|---|---|
| Solicitações.ai | Acesso LLM centralizado, ferramentas FinOps econômicas | Empresas que buscam eficiência de custos | Preços personalizados |
| Máxima IA | Métricas pré-construídas, suporte a sistemas multiagentes | Equipes gerenciando fluxos de trabalho complexos de IA | US$ 29/assento/mês |
| Confiança cerebral | Ferramentas de depuração, testes de conversação multivoltas | Equipes de engenharia | US$ 249/mês |
| Arize IA | Rastreamento detalhado e de código aberto, verificações de alucinações | Organizações priorizando o controle de dados | Gratuito (auto-hospedado) |
| Lang Smith | Integração LangChain, versionamento imediato | Usuários LangChain | Pague conforme o uso |
Essas plataformas simplificam o gerenciamento de LLM, garantindo operações de IA escalonáveis, confiáveis e econômicas.
__XLATE_5__
Prompts.ai brings together 35+ top-tier LLMs - including GPT‑5, Claude, LLaMA, and Gemini - into one unified platform designed for enterprise-level prompt engineering and detailed output analysis. It simplifies evaluation with automated testing pipelines.
Prompts.ai apresenta pipelines de avaliação capazes de executar mais de 20 testes em conjuntos de dados de prompt. Isso inclui métodos como afirmações LLM (usando IA para avaliar resultados), verificações de similaridade semântica por meio de similaridade de cosseno, avaliações de correspondência exata e correspondência de padrões baseada em regex. As equipes também podem incorporar avaliações humanas por meio de um painel fácil de usar, permitindo que especialistas do domínio avaliem manualmente os resultados como parte do aprendizado reforçado a partir do feedback humano.
For instance, Gorgias, a customer support platform, used Prompts.ai to scale its AI-powered helpdesk to support millions of shoppers. This led to a 20× boost in automation. Their ML engineers and support teams run daily regression tests on backtest datasets to catch potential issues before deployment.
Esses recursos de testes rigorosos garantem uma integração tranquila aos fluxos de trabalho atuais.
Prompts.ai’s evaluation pipelines seamlessly integrate with CI/CD workflows and enable backtesting against historical production data. The platform supports connections through external HTTP endpoints, custom Python/JavaScript scripts, and Model Context Protocol (MCP) actions.
Speak, um aplicativo de aprendizagem de idiomas, aproveitou esses recursos de automação para condensar meses de desenvolvimento curricular em apenas uma semana. Essa eficiência permitiu-lhes lançar recursos baseados em IA em 10 novos mercados ao mesmo tempo.
Prompts.ai também ajuda as equipes a otimizar custos, oferecendo visualizações de comparação de modelos lado a lado. Essas comparações permitem que os usuários avaliem as compensações entre custos de API, latência e índices de qualidade. As equipes podem resumir os resultados ou usar modelos menores e mais rápidos para tarefas intermediárias para reduzir o uso de tokens. A NoRedInk, que atende 60% dos distritos escolares dos EUA, usa esses recursos de economia de custos para fornecer feedback gerado por IA sobre mais de 1 milhão de notas de alunos, ao mesmo tempo em que mantém a qualidade do professor.
Prompts.ai aprimora a colaboração equipando todas as partes interessadas com ferramentas para refinar os resultados do LLM. Um editor visual sem código permite que usuários não técnicos editem e testem prompts sem depender de engenheiros. O Prompt Registry centralizado garante um gerenciamento eficiente de versões.
O ParentLab, por exemplo, economizou mais de 400 horas de engenharia em apenas seis meses ao permitir que especialistas de domínio não técnico gerenciassem 700 revisões imediatas.
__XLATE_12____XLATE_13__
A plataforma também reúne classificações de usuários e as traduz em pontuações de desempenho, criando um ciclo de feedback contínuo para melhorar a qualidade da produção em todos os modelos integrados.
Maxim AI fornece ferramentas de teste e monitoramento aprofundadas, combinando avaliações conduzidas por máquinas com feedback humano para apoiar equipes no gerenciamento de fluxos de trabalho de IA complexos. Seus recursos são projetados para garantir avaliações completas, que são cruciais para manter um forte desempenho do LLM.
Maxim AI usa uma estrutura de avaliação robusta que inclui testes determinísticos, métodos estatísticos e ferramentas de julgamento automatizadas. O Loja de Avaliadores oferece métricas pré-construídas como RAGAS, adaptadas para sistemas de geração aumentada de recuperação – componentes-chave em cerca de 60% das aplicações de IA de produção até 2026. Além disso, métricas em nível de nó help identify failures in retrieval and generation processes. The platform’s Simulação de Agente O mecanismo permite testes de conversa em vários turnos e criação de persona do usuário para avaliações pré-implantação. Empresas como Clinc e Mindtickle relataram uma redução de 75% no tempo de produção ao adotar esses padrões de qualidade.
Maxim AI’s evaluation tools integrate effortlessly with today’s development environments. It supports SDKs in Python, TypeScript, Java, and Go, while offering compatibility with platforms like LangChain, LangGraph, Crew AI, OpenAI, Anthropic, Mistral, and AWS Bedrock. The platform also adheres to OpenTelemetria padrões para rastreamento distribuído e se conecta a ferramentas como Slack e PagerDuty para alertas em tempo real. Os usuários corporativos se beneficiam de opções de implantação que incluem hospedagem em nuvem e In-VPC, todas atendendo aos requisitos de conformidade SOC2, HIPAA e GDPR.
O Gateway Bifrost LLM usa cache semântico para reduzir despesas, enquanto monitora o uso de tokens e os custos de API para identificar e lidar com fluxos de trabalho caros. Isso garante operações eficientes à medida que a produção aumenta.
Maxim AI’s UI sem código capacita gerentes de produto e designers a experimentarem prompts e conduzirem avaliações de forma independente. Kellie Maloney, líder de produto da Rise Science, compartilhou:
__XLATE_29__
A plataforma também inclui filas de anotação para revisões humanas, um Prompt CMS centralizado com controle de versão e RBAC com suporte SAML/SSO. As equipes que utilizam essas ferramentas de colaboração alcançaram um aumento de cinco vezes na velocidade de envio, simplificando a iteração e acelerando as implementações de produção.
Braintrust combina experimentos offline com pontuação online para dar às equipes uma visão completa do desempenho do LLM, desde o desenvolvimento até a implantação.
Braintrust fornece várias maneiras de avaliar a qualidade da produção em uma escala de 0 a 1. As equipes podem usar pontuadores automatizados para tarefas como verificações de factualidade e similaridade, confiar em avaliações LLM como juiz ou implementar lógica de código personalizada adaptada às suas necessidades específicas. A plataforma inclui Visualizações da linha do tempo com gráficos de Gantt para identificar gargalos, Visualizações de tópicos para depuração de conversas multivoltas e visualizações de rastreamento baseadas em linguagem natural exibidas como componentes React em área restrita. Ele também oferece suporte à execução de vários testes para cada entrada, ajudando as equipes a medir a variação e manter a consistência.
Braintrust integra-se perfeitamente com as principais estruturas de IA, oferecendo suporte nativo para Mais de 9 estruturas principais, como OpenTelemetry, Vercel AI SDK, OpenAI Agent SDK, Instructor, LangChain, LangGraph, Google ADK, Mastra e Pydantic AI. Ele usa um "envoltório" abordagem para integração - exemplos incluem envolverAISDK para Vercel AI SDK (abrangendo as versões v3 a v6 beta) e wrap_openai para Instrutor. A plataforma segue Convenções semânticas do OpenTelemetry GenAI, mapeando automaticamente detalhes como uso de token e identificadores de modelo para campos do Braintrust. Funciona perfeitamente com os principais provedores de LLM, incluindo OpenAI, Anthropic e Google Gemini. Os desenvolvedores também podem usar o Avaliação() função ou a CLI com o --assistir sinalizador para executar novamente as avaliações automaticamente sempre que os arquivos forem atualizados durante o desenvolvimento.
Braintrust vai além da avaliação, promovendo a colaboração em equipe com ferramentas integradas. Isso é sincronização bidirecional garante que os gerentes de produto e engenheiros possam trabalhar nos prompts de forma intercambiável entre código e UI. O Parque infantil oferece um espaço sem código onde as equipes podem testar prompts, comparar modelos lado a lado e compartilhar configurações para iterações rápidas. Ferramentas de anotação dedicadas permitem que as equipes forneçam feedback humano, adicionando rótulos ou correções diretamente aos traços e resultados do modelo. Anotadores externos podem ser convidados para avaliar a qualidade em diferentes versões do modelo, enquanto os backlogs de avaliação compartilhados centralizam conjuntos de dados e rubricas de pontuação, eliminando a necessidade de rastreamento manual em planilhas.
Phoenix da Arize AI é uma plataforma de código aberto projetada para fornecer às equipes controle abrangente sobre a avaliação de grandes modelos de linguagem (LLMs). Construído com OpenTelemetry em sua essência, Phoenix atraiu atenção com mais de 2,5 milhões de downloads e mais de 8.500 estrelas no GitHub. Ele oferece rastreamento detalhado para rastrear cada etapa de um fluxo de trabalho LLM, facilitando a identificação de onde surgem os problemas.
Phoenix emprega o LLM como juiz abordagem, usando modelos básicos de OpenAI, Anthropic e Gemini para avaliar outras aplicações LLM para fatores como relevância, toxicidade e desempenho geral. Ele vem com avaliadores pré-construídos para tarefas comuns, como geração aumentada de recuperação (RAG) e chamada de função. Uma característica de destaque é a sua capacidade de explicação, onde os modelos de avaliação fornecem um raciocínio claro por trás de suas pontuações, ajudando os desenvolvedores a compreender a lógica por trás de cada avaliação. Ferramentas adicionais incluem verificações determinísticas baseadas em código, anotações humanas diretamente na interface e cluster de conjunto de dados que usa embeddings para agrupar visualmente perguntas e respostas semanticamente semelhantes. Esse agrupamento ajuda a isolar áreas onde os modelos apresentam desempenho inferior.
__XLATE_63__
Estas ferramentas de avaliação integram-se perfeitamente com o ecossistema de desenvolvimento mais amplo da plataforma.
Phoenix oferece suporte à instrumentação automática para estruturas populares como LlamaIndex, LangChain, DSPy, Mastra e Vercel AI SDK. Ele funciona com Python, TypeScript e Java, e seu design nativo do OpenTelemetry garante compatibilidade com ferramentas de observabilidade existentes sem prender os usuários a fornecedores específicos. As equipes também podem incorporar avaliações de bibliotecas de terceiros, como Ragas, Deepeval ou Cleanlab, oferecendo flexibilidade em seus fluxos de trabalho.
Phoenix foi construído para ser eficiente, oferecendo execuções de avaliação até 20x mais rápidas por meio de simultaneidade e lote. Seu Prompt Playground fornece um ambiente de teste onde as equipes podem refinar os prompts e comparar variantes de modelos lado a lado antes da implantação, reduzindo o risco de erros de produção dispendiosos.
Como uma plataforma totalmente de código aberto e auto-hospedada, o Phoenix garante que as equipes mantenham controle total sobre seus dados. Recursos como filas de anotação humana permitir que rótulos verdadeiros sejam adicionados diretamente aos rastreamentos, promovendo uma melhor colaboração. O Centro de prompt gerencia o versionamento imediato, o armazenamento e a implantação em ambientes, enquanto o Bate-papo de extensão A ferramenta permite que as equipes avaliem e discutam segmentos específicos do fluxo de trabalho para descobrir problemas de desempenho. Com uma comunidade Slack de mais de 7.000 membros, os usuários têm acesso a uma rede para solucionar problemas e compartilhar insights.
__XLATE_76__
LangSmith é uma plataforma versátil projetada para funcionar perfeitamente com ou sem LangChain, tornando-a adaptável a qualquer pilha LLM. Ele se conecta facilmente a ferramentas como OpenAI, Anthropic, CrewAI, Vercel AI SDK e Pydantic AI, proporcionando flexibilidade para equipes que já usam estruturas específicas. A plataforma atende aos padrões de conformidade, como HIPAA, SOC 2 Tipo 2 e GDPR, e usa um processo assíncrono para enviar rastreamentos, garantindo nenhuma latência adicional para os usuários finais.
LangSmith oferece dois modos de avaliação para atender a diferentes necessidades: Avaliação offline para testar conjuntos de dados selecionados durante o desenvolvimento e Avaliação online para monitorar o tráfego de produção ao vivo. Suporta quatro tipos de avaliadores:
A plataforma inclui ferramentas de análise avançadas como Visualização de diferenças, que destaca diferenças entre resultados de modelos e textos de referência, e comparações lado a lado para avaliação comparativa de desempenho. Também fornece agrupamento de metadados, permitindo a análise de métricas como precisão ou custo por categorias como área de assunto ou tipo de usuário. LangSmith integra-se com o código aberto openevals pacote, oferecendo avaliadores pré-construídos para avaliar a correção e a brevidade.
Esses recursos facilitam a integração do LangSmith em fluxos de trabalho e ferramentas de desenvolvimento existentes.
LangSmith simplifica o rastreamento com o @rastreável decorador ou wrappers de cliente que capturam automaticamente entradas e saídas. Ele oferece suporte à integração com SDKs Python e TypeScript/JavaScript, uma API REST e estruturas de teste como pytest, Vitest e Jest, facilitando a incorporação de avaliações em pipelines de CI/CD. Além disso, a integração do OpenTelemetry permite que as equipes enviem rastreamentos de pipelines de observabilidade existentes diretamente para o LangSmith.
LangSmith aprimora a colaboração em equipe com feedback intuitivo e ferramentas de anotação. Filas de anotação habilite o roteamento automático de execuções específicas para especialistas no assunto para revisão manual e pontuação com base em critérios personalizados. O Centro de prompt serve como um espaço centralizado para as equipes iterarem, criarem versões e compartilharem prompts, completo com recursos de rastreamento de alterações e reversão para manter a consistência durante todo o desenvolvimento. Os recursos de anotação em linha permitem que os membros da equipe sinalizem problemas ou forneçam feedback direcionado sobre a qualidade da resposta, melhorando a precisão da avaliação e a eficiência do fluxo de trabalho.
A plataforma também oferece gerenciamento detalhado de usuários e isolamento de carga de trabalho, garantindo uma colaboração tranquila entre as equipes. Os usuários podem se inscrever gratuitamente em smith.langchain.com - sem necessidade de cartão de crédito. Para uso em produção, LangSmith opera com base no pagamento conforme o uso, com planos empresariais disponíveis para auto-hospedagem em clusters Kubernetes em AWS, GCP ou Azure.
Ao avaliar plataformas para avaliação LLM, é essencial considerar a compatibilidade técnica, o custo e os métodos de avaliação. Aqui está uma visão mais detalhada das opções:
Solicitações.ai reúne mais de 35 modelos líderes em uma interface segura, oferecendo controles FinOps que podem reduzir os custos de software de IA em até 98%. Confiança cerebral simplifica a configuração com um AI Proxy de configuração zero, capturando logs por meio de um único URL base. Inclui 1 milhão de períodos de rastreamento gratuitos, com planos pagos a partir de US$ 249/mês. Máxima IA integra-se perfeitamente às pilhas de observabilidade existentes, concentrando-se na pontuação de qualidade em vez do rastreamento completo. Oferece um plano gratuito para até 10.000 registros por mês e planos pagos a partir de US$ 29 por assento/mês. Arize Phoenix suporta auto-hospedagem para privacidade de dados, integrando-se com ferramentas como RAGAS e Giskard para análises métricas mais profundas. Lang Smith é feito sob medida para usuários do LangChain, fornecendo observabilidade avançada, embora os preços do suporte empresarial variem. Notavelmente, o Notion melhorou dez vezes sua velocidade de desenvolvimento com o Braintrust, passando de 3 para 30 problemas diários.
A abordagem exclusiva de cada plataforma simplifica a tomada de decisões com base nas suas necessidades específicas de avaliação. Veja como eles se comparam em termos de métodos de avaliação, integração e implantação:
A complexidade da integração também desempenha um papel fundamental. A configuração baseada em proxy do Braintrust é simples - basta atualizar o URL base da API. Maxim AI integra-se com ferramentas de observabilidade existentes, enquanto a forte integração LangChain da LangSmith atende a necessidades especializadas de observabilidade. Arize Phoenix se destaca por organizações que priorizam a soberania dos dados, oferecendo uma solução auto-hospedada e de código aberto. Enquanto isso, Prompts.ai fornece controles de governança de nível empresarial e trilhas de auditoria completas para uma operação segura.
__XLATE_111__
Para obter insights rápidos, implantações baseadas em proxy e integrações profundas simplificam o processo. Os usuários do LangChain acharão o LangSmith uma opção natural, enquanto as organizações que gerenciam dados confidenciais podem optar por soluções de código aberto como Arize Phoenix ou Prompts.ai para governança robusta e recursos de auditoria.
Com base nas avaliações fornecidas, cada plataforma oferece vantagens distintas para refinar a análise de resultados do LLM. Solicitações.ai oferece às empresas acesso centralizado a modelos líderes, combinados com controles FinOps que podem reduzir os custos de IA em até 98%, garantindo ao mesmo tempo governança robusta e capacidades de auditoria. Confiança cerebral é feito sob medida para equipes de engenharia em ritmo acelerado, com empresas como a Notion relatando um aumento de 10 vezes na velocidade de desenvolvimento - aumentando a resolução de problemas de 3 para 30 por dia. Da mesma forma, as equipes da Stripe e da Airtable observaram ganhos de precisão de mais de 30% semanas após a adoção da plataforma.
Para aqueles profundamente integrados ao ecossistema LangChain, Lang Smith fornece integração sem esforço e opções rápidas de prototipagem. Máxima IA atende equipes focadas no gerenciamento de sistemas multiagentes complexos, oferecendo ferramentas de pontuação precisas e um gateway de baixa latência que introduz apenas 11 microssegundos de sobrecarga em um volume de 5.000 solicitações por segundo. Enquanto isso, Arize Phoenix é ideal para organizações que priorizam a soberania dos dados, fornecendo uma solução auto-hospedada e de código aberto que se adapta perfeitamente aos sistemas de observabilidade existentes.
Cada plataforma aborda desafios críticos no desempenho do LLM e no gerenciamento de custos. Com as empresas enfrentando perdas potenciais de US$ 1,9 bilhão anualmente devido a falhas de LLM não detectadas na produção, a necessidade de ir além das avaliações subjetivas para métricas mensuráveis e baseadas em dados tornou-se essencial para garantir confiabilidade e eficiência.
Essas ferramentas elevam o desenvolvimento do LLM a uma disciplina de engenharia estruturada. Quer seu foco seja lidar com trilhões de eventos mensalmente, simplificar a colaboração entre equipes ou manter o controle sobre a infraestrutura auto-hospedada, a escolha da plataforma certa garante que seus fluxos de trabalho LLM alcancem a confiabilidade, a qualidade e a economia necessárias para atingir seus objetivos.
Essas plataformas são projetadas para ajudar as organizações a reduzir despesas com IA, oferecendo ferramentas para monitorar e ajustar o uso de grandes modelos de linguagem (LLMs). Por exemplo, soluções como Prompts.ai permitem que os usuários rastreiem o uso de tokens em tempo real, tornando mais fácil detectar e reduzir o consumo desnecessário de tokens. Isso ajuda a evitar gastos excessivos com chamadas de API excessivas, levando a um melhor gerenciamento de custos.
Além do controle de custos, essas plataformas também fornecem informações valiosas sobre o desempenho e a qualidade da produção. Eles podem ajudar a detectar e prevenir problemas como alucinações ou erros, que poderiam levar a um retrabalho caro. Ao analisar tendências de uso e identificar ineficiências, as organizações podem simplificar fluxos de trabalho, reduzir custos operacionais e garantir resultados consistentes e de alta qualidade. Tudo isto apoia decisões mais inteligentes e baseadas em dados para uma gestão eficaz dos orçamentos de IA.
As plataformas LLM oferecem várias maneiras de conectar-se perfeitamente com ferramentas e fluxos de trabalho, atendendo a diferentes necessidades. Muitas plataformas suportam integração nativa por meio de SDKs como Python e JavaScript, juntamente com estruturas como LangChain e LangServe. Isso torna a incorporação de LLMs em aplicativos personalizados simples e eficiente. Para monitoramento, as plataformas geralmente suportam padrões abertos como OpenTelemetry, garantindo compatibilidade com a infraestrutura existente.
Algumas plataformas também se integram a ferramentas de CI/CD, como GitHub Actions e Jenkins, simplificando os processos de teste e implantação. Para organizações que priorizam o controle sobre seu ambiente, estão disponíveis opções de auto-hospedagem, permitindo personalização e mantendo a segurança dos dados. Esses recursos de integração permitem que os usuários aumentem a eficiência, monitorem o desempenho de forma eficaz e implementem LLMs com segurança em suas operações.
Para aqueles que valorizam privacidade e controle de dados, OnPrem.LLM oferece uma excelente solução. Projetada especificamente para tarefas sensíveis à privacidade, esta plataforma permite que modelos de linguagem grandes (LLMs) lidem com dados confidenciais ou restritos com segurança em ambientes offline. Ao permitir a execução totalmente local, reduz significativamente as chances de exposição de dados, ao mesmo tempo que oferece integração opcional na nuvem para configurações híbridas quando necessário.
Com sua interface intuitiva e sem código, OnPrem.LLM garante acessibilidade para usuários sem conhecimento técnico, ao mesmo tempo que mantém supervisão completa do gerenciamento de dados. Isto o torna a escolha ideal para organizações em setores regulamentados ou sensíveis, onde a proteção das informações é uma prioridade máxima.



















