Pague Conforme o Uso - AI Model Orchestration and Workflows Platform

AI workflows in 2026 face challenges like fragmented tools, unchecked model drift, and escalating costs. To overcome these, organizations are adopting smarter, automated workflows that unify tools, improve governance, and optimize spending. Here’s how you can transform your AI operations:
Estas práticas simplificam os fluxos de trabalho, melhoram a supervisão e reduzem custos, permitindo que as organizações dimensionem a IA de forma responsável e eficiente.
__XLATE_1__
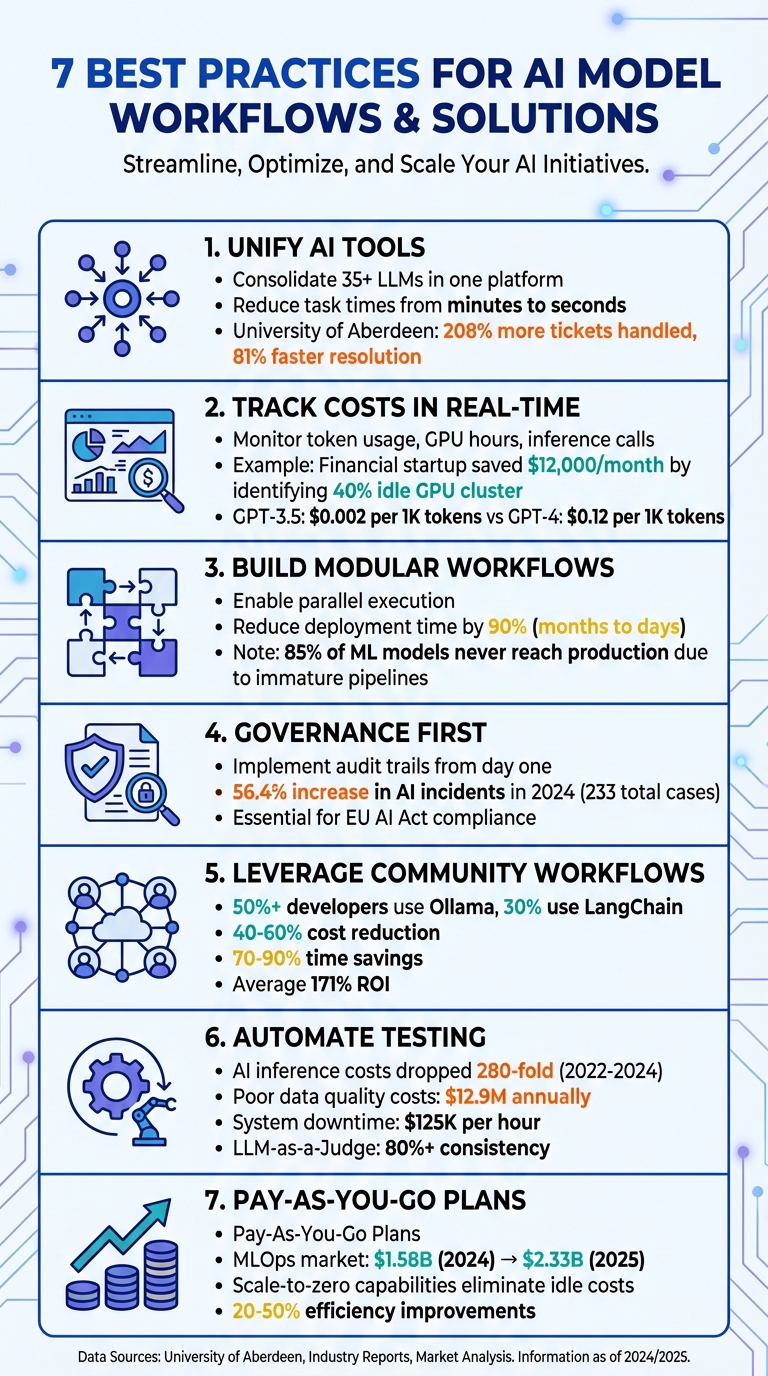
Gerenciar plataformas separadas para modelos como GPT-5, Claude, LLaMA e Gemini pode desacelerar as operações e criar obstáculos desnecessários. Ao consolidar mais de 35 LLMs em uma interface, Prompts.ai elimina o incômodo de lidar com vários logins e credenciais, reduzindo o tempo de tarefa de minutos para meros segundos.
Esse tipo de integração gera ganhos mensuráveis de produtividade. Por exemplo, quando a Universidade de Aberdeen adotou um sistema baseado em IA em setembro de 2025, sua equipe de TI conseguiu lidar com 208% mais tickets e reduziu o tempo de resolução em 81% [1]. Esses resultados destacam como um sistema simplificado permite que as equipes se concentrem nos resultados, em vez de perder tempo gerenciando ferramentas fragmentadas. Essa abordagem abre caminho para fluxos de trabalho de IA mais eficientes, confiáveis e econômicos.
Uma interface unificada não apenas economiza tempo, mas também garante maior confiabilidade e flexibilidade. Com todos os modelos acessíveis a partir de uma única plataforma, as equipes podem alternar facilmente entre os mecanismos, mantendo a continuidade mesmo se um modelo falhar ou fornecer resultados imprecisos. Essa configuração proativa evita processos descontrolados, que podem levar ao aumento vertiginoso dos custos da nuvem quando agentes automatizados fazem loop sem os controles adequados.
A plataforma também permite testes de desempenho lado a lado, para que você possa avaliar qual modelo melhor se adapta a tarefas específicas. Por exemplo, as consultas de suporte ao cliente podem ser encaminhadas para um LLM, os projetos criativos para outro e o processamento de dados para um terceiro - tudo gerenciado no mesmo painel. Esse design independente de modelo garante que você não fique preso às limitações ou preços de um único fornecedor, proporcionando a liberdade de otimizar o desempenho e os custos.
Prompts.ai leva o gerenciamento de custos para o próximo nível, oferecendo insights em tempo real sobre o uso de tokens em todos os modelos. Esta transparência ajuda a evitar derrapagens orçamentais antes que elas aconteçam. Uma camada FinOps integrada rastreia os gastos imediatamente, facilitando a identificação de quais fluxos de trabalho agregam valor e quais drenam recursos. As organizações que utilizam a automação do fluxo de trabalho de IA relataram um ROI de 84% quando conseguem vincular as despesas aos resultados do negócio. A Databricks, por exemplo, reduziu os tickets de suporte em 23% por meio de triagem inteligente alimentada por modelos de dados limpos e rastreamento transparente de custos [1].
Os créditos TOKN pré-pagos da plataforma alinham as despesas com o uso real, eliminando a necessidade de pagar pela capacidade não utilizada. Ao consolidar os custos em vários modelos, as equipes podem economizar até 98% em comparação com a manutenção de assinaturas separadas para cada ferramenta, gerando economias significativas em projetos e departamentos.
Prompts.ai também fortalece a governança e a conformidade, oferecendo trilhas de auditoria unificadas que atendem tanto aos requisitos regulatórios quanto às melhorias no fluxo de trabalho. A plataforma categoriza as tarefas em níveis de risco, garantindo que as operações de alto risco (como tarefas de nível 4 com potencial catastrófico) permaneçam sob supervisão humana até que os sistemas de IA sejam totalmente confiáveis.
Com criptografia ponta a ponta e controles de acesso rígidos, os dados confidenciais permanecem protegidos contra configurações incorretas ou violações. Como 78% das organizações agora usam IA em pelo menos uma área de seus negócios [2], o Prompts.ai fornece segurança de nível empresarial, ao mesmo tempo que mantém a velocidade e agilidade que as equipes precisam para inovar. Cada interação é segura, rastreável e auditável, dando às organizações a confiança necessária para dimensionar a IA de forma responsável.
As cargas de trabalho de IA geralmente levam a despesas imprevisíveis que não podem ser totalmente compreendidas por meio de faturas mensais. O FinOps em tempo real muda isso, oferecendo insights imediatos sobre os custos à medida que eles ocorrem. Ao rastrear o uso de tokens, horas de GPU e chamadas de inferência quase em tempo real, as equipes podem identificar e resolver estouros de orçamento antes que eles saiam do controle.
Por exemplo, uma startup de análise financeira descobriu que 40% de seu cluster de 8 GPUs estava ocioso, desperdiçando quase US$ 12.000 por mês. Através do monitoramento em tempo real, a equipe identificou essa ineficiência no meio do sprint e fez ajustes para otimizar a capacidade imediatamente.
O rastreamento granular por equipe, projeto ou cliente refina ainda mais os modelos de estorno. Ao anexar metadados, como IDs de clientes, às solicitações de API, os gastos se tornam mais transparentes. Isto permite que os departamentos paguem apenas pelo que utilizam, abrindo caminho para operações que sejam escaláveis e económicas.
Real-time tracking doesn’t just monitor costs - it actively supports smarter scaling decisions. Autoscaling can now factor in both performance metrics (like latency) and financial data (such as cost per prediction). For example, during traffic spikes, systems can throttle or reroute requests based on cost signals, ensuring resources are used efficiently.
__XLATE_13__
StreamForge AI adotou essa estratégia em setembro de 2025 integrando Kubecost com Prometheus e exibindo dados de utilização em painéis Grafana atualizados a cada cinco minutos. Usando uma abordagem de escalonamento automático de sinalização dupla – equilibrando a latência p95 e as métricas de custo por solicitação – eles aumentaram significativamente a utilização da GPU e melhoraram a relação custo-benefício de mais de 300 trabalhos de treinamento diários. Essa abordagem em tempo real ajuda a evitar configurações incorretas dispendiosas que poderiam esgotar os orçamentos mensais.
Centralizing cost tracking across multiple AI providers is essential when managing diverse models. A unified AI gateway simplifies this process by consolidating token usage, latency, and cost data into a single, reliable source. Whether you’re using OpenAI, Anthropic, or self-hosted models, this centralized system eliminates the need to piece together fragmented billing data.
Este nível de integração é crucial porque diferentes modelos têm preços muito diferentes. Por exemplo, o GPT-3.5-Turbo custa cerca de US$ 0,002 por 1.000 tokens, enquanto o GPT-4 pode ir até US$ 0,12 por 1.000 tokens, dependendo da janela de contexto. O rastreamento em tempo real permite que as equipes comparem esses custos e encaminhem as tarefas para o modelo mais econômico. Seja para lidar com consultas simples de clientes ou análises complexas, as tarefas são atribuídas ao modelo certo com base em dados de custos em tempo real, garantindo que os fluxos de trabalho permaneçam eficientes e econômicos.
A divisão dos fluxos de trabalho de IA em componentes modulares revoluciona a forma como eles são implantados e dimensionados. Em vez de depender de um pipeline único e rígido para lidar com cada estágio, uma abordagem modular permite que peças individuais sejam atualizadas ou substituídas sem interromper todo o sistema.
Esse design também permite a execução paralela, onde várias tarefas podem ser executadas ao mesmo tempo. Por exemplo, um serviço de tradução multilíngue pode processar versões de vários idiomas simultaneamente, em vez de uma após a outra, reduzindo significativamente o tempo de processamento. A adoção de práticas MLOps acelera ainda mais a implantação, reduzindo o tempo para mover um modelo para produção em até 90%. Pipelines automatizados podem reduzir os prazos de implantação de meses para apenas alguns dias.
Outra vantagem é a repetibilidade. Se uma etapa específica, como o pós-processamento, encontrar um problema, você poderá executar novamente apenas esse módulo usando artefatos armazenados em vez de refazer todo o fluxo de trabalho. Essa abordagem de reexecução direcionada economiza tempo e recursos, especialmente para tarefas que exigem poder computacional significativo. Os fluxos de trabalho modulares também facilitam a padronização e a integração segura de componentes em todo o sistema.
Depois que uma base modular estiver instalada, garantir uma comunicação suave entre os componentes torna-se essencial. A padronização dos formatos de entrada e saída ajuda a evitar erros em cascata. Por exemplo, se um módulo de ingestão de dados gerar um arquivo JSON claramente definido que se alinhe perfeitamente com a entrada esperada de um módulo de inferência, possíveis falhas de comunicação serão eliminadas.
Separar a lógica da IA da lógica da política melhora ainda mais a capacidade de manutenção. Isso permite gerenciar o comportamento do modelo dinâmico independentemente de regras de negócios fixas, conforme destacado no AWS Prescriptive Guidance. Ferramentas como Docker ou Kubernetes podem conteinerizar módulos, garantindo que permaneçam portáteis em diferentes ambientes. Um módulo conteinerizado pode operar de forma consistente no desenvolvimento, preparação e produção, e pode até mesmo fazer a transição entre provedores de nuvem sem exigir alterações. Para orquestração, o AWS Step Functions fornece coordenação sem servidor com novas tentativas integradas, enquanto o Apache Airflow oferece flexibilidade baseada em Python para gerenciar fluxos de trabalho mais complexos.
Projetos modulares também trazem benefícios financeiros, permitindo alocar os recursos certos para cada tarefa. Modelos de raciocínio complexos, que consomem muitos recursos, podem ser reservados para análises exigentes, enquanto tarefas mais simples são realizadas por modelos menos dispendiosos. Isso garante que os recursos computacionais sejam usados com sabedoria.
O rastreamento de metadados no nível do módulo aumenta a transparência. Ao anexar detalhes como carimbos de data/hora, versões de modelos e dados de custo a cada artefato à medida que ele avança no pipeline, as equipes obtêm uma trilha de auditoria clara. Isso não apenas ajuda na depuração, mas também no acompanhamento financeiro. O alinhamento dos custos com métricas específicas do módulo permite um orçamento preciso, mantendo a flexibilidade. Além disso, definir limites para tamanhos de lote e simultaneidade pode ajudar a evitar despesas inesperadas durante períodos de alta demanda.
It’s worth noting that about 85% of machine-learning models never make it to production, often due to immature pipeline structures. Modular, iterative workflows offer a way to overcome this challenge. Teams can start small, validate one module at a time, and gradually scale up, reducing risks and ensuring systems are ready for production.
Incorporar governança em seu fluxo de trabalho de IA desde o início evita ajustes dispendiosos no futuro. Ao aproveitar as avaliações automatizadas e a transparência discutidas anteriormente, você pode garantir que a conformidade seja incorporada aos seus processos desde o início. Assim que um modelo ou caso de uso é criado, gere um ticket de rastreamento em sua ferramenta de fluxo de trabalho e atribuir um nível de risco inicial. Aplicações de alto risco, como pontuação de crédito ou sistemas de contratação, exigem processos de aprovação mais rigorosos e monitoramento mais próximo em comparação com ferramentas de menor risco usadas internamente. Este "deslocamento para a esquerda" abordagem mantém você preparado para os requisitos regulatórios, especialmente com estruturas como a Lei de IA da UE, que exige documentação detalhada dos processos de treinamento e avaliação.
Uma pedra angular da conformidade é rastreamento de linhagem, que fornece um caminho claro e reproduzível desde os dados brutos até a saída final do modelo. Combine rastreamento de linhagem com rastreabilidade de instantâneo, garantindo que o estado exato do seu código, dados e configurações seja preservado antes da implantação. Isso permite reproduzir qualquer versão do modelo conforme necessário. A investigação da indústria destaca a urgência destas medidas, observando um aumento de 56,4% nos incidentes relacionados com IA em 2024, totalizando 233 casos – enfatizando a necessidade de pistas de auditoria robustas.
As trilhas de auditoria simplificam a solução de problemas, vinculando diretamente os erros às suas origens. Em vez de examinar os registros manualmente, os engenheiros podem usar o rastreamento de linhagem para identificar rapidamente onde um pipeline quebrou ou a qualidade dos dados diminuiu. A automatização de tarefas de governança, como verificações de ativos e avaliações de risco, não apenas garante a conformidade, mas também mantém suas iniciativas de IA em andamento com eficiência à medida que crescem. Ao automatizar essas etapas, você pode reduzir os tempos de aprovação e manter a consistência entre as operações.
Uma governação de dados forte é essencial para manter dados de alta qualidade. O gerenciamento centralizado de metadados consolida informações sobre todos os ativos de IA em um só lugar, eliminando redundâncias e garantindo operações tranquilas. Quando cada componente, desde prompts até versões de modelo, é rastreado com carimbos de data e hora e detalhes de custo, as equipes ganham uma histórico de execução abrangente. Isso torna os pipelines mais fáceis de reproduzir e refinar. Os registros de auditoria automatizados reduzem ainda mais o erro humano, estabelecendo um fluxo de trabalho confiável e repetível.
Essas estratégias de governança integram-se perfeitamente aos fluxos de trabalho modulares, garantindo que a conformidade continue sendo uma parte essencial do seu sistema à medida que ele é dimensionado.
Uma camada de governança unificada une fluxos de trabalho simplificados e transparência de custos, garantindo conformidade geral. Muitos sistemas – como Snowflake, Databricks, plataformas de nuvem e ambientes de borda – operam em diversas plataformas. Sem uma abordagem de governança unificada, você corre o risco de ter uma “IA sombra”, onde os modelos são implantados sem supervisão, impossibilitando a verificação de conformidade. Rastreabilidade entre sistemas garante que a linhagem de dados de tempo de execução seja capturada em consultas, notebooks, trabalhos e painéis, mantendo a conformidade à medida que os dados se movem entre plataformas. Interfaces padronizadas, como o Model Context Protocol (MCP) com gateways centralizados, permitem registro consistente e rastreamento de solicitações entre servidores e locatários. Isso lhe dá uma trilha de auditoria completa, não importa onde o trabalho seja realizado.
Criar fluxos de trabalho do zero pode ser demorado e ineficiente. Estruturas orientadas pela comunidade, como LangChain e Ollama tornaram-se soluções essenciais, oferecendo modelos pré-construídos para encadear prompts e integrar ferramentas. Essas estruturas são amplamente adotadas, com mais de 50% dos desenvolvedores usando Ollama e quase um terço contando com LangChain para gerenciar agentes de IA. Eles substituem códigos personalizados frágeis por funções flexíveis e sem servidor que operam de forma independente, facilitando o gerenciamento e a escalabilidade.
O principal benefício é escalabilidade sem complexidade. Ao confiar em padrões testados pela comunidade, você pode alternar modelos (como migrar do GPT para o Amazon Bedrock) sem revisar sua lógica de orquestração. Essa flexibilidade acelera a implantação, mantendo a consistência. A pesquisa mostra que, embora a orquestração seja uma prioridade para muitas organizações, apenas algumas a implementaram totalmente. Os fluxos de trabalho comunitários oferecem uma solução prática, permitindo a integração perfeita entre várias plataformas de IA.
Os fluxos de trabalho comunitários também abordam o desafio de integração de ferramentas de IA entre plataformas. Padrões como o Protocolo de Contexto do Modelo (MCP) abordar a questão da expansão das plataformas, uma preocupação para 63% dos executivos. Esses protocolos permitem que agentes e ferramentas de IA trabalhem juntos em plataformas como Gmail, Slack e CRMs sem exigir entrada manual de dados. Por exemplo, uma solicitação simples em linguagem natural, como "resuma os últimos 10 e-mails do Gmail" - pode acionar tarefas estruturadas com conexões API pré-configuradas.
__XLATE_52__
A interoperabilidade é crítica, com 87% dos líderes de TI identificando-o como essencial para a adoção de sistemas baseados em IA. Os fluxos de trabalho da comunidade são projetados tendo em mente a resiliência, oferecendo recursos como novas tentativas automatizadas, tempos limite e execução paralela para lidar com possíveis falhas de modelo. Estas salvaguardas são vitais, especialmente porque 87% dos desenvolvedores se preocupam com a precisão da IA, e 81% estão preocupados com segurança e privacidade. Além de melhorar a integração, esses fluxos de trabalho também ajudam a reduzir significativamente os custos.
Usar modelos de comunidade para transformar prompts de linguagem natural em fluxos de trabalho automatizados pode reduzir drasticamente custos e economizar tempo. Relatório de organizações Reduções de custos de 40-60% e 70-90% de economia de tempo quando adotam a automação de IA por meio desses fluxos de trabalho. Começar com soluções testadas elimina a necessidade de processos dispendiosos de tentativa e erro.
Esses fluxos de trabalho também aumentam a transparência ao incorporar trilhas de auditoria padronizadas e rastreamento de metadados. Eles registram automaticamente detalhes como fontes de dados, permissões e históricos de decisões dos agentes. Muitos incluem humano no circuito pontos de verificação para revisão manual de tarefas sensíveis ou de alto custo, garantindo a supervisão onde é mais importante. Ao gerenciar os custos de inferência durante o dimensionamento, as empresas observaram uma média ROI de 171% ao aproveitar fluxos de trabalho criados pela comunidade.
Automatizar testes e avaliações é a peça final na criação de um ciclo de vida de IA contínuo. Elimina os atrasos causados por testes manuais, que muitas vezes impedem que os modelos cheguem à produção – 85% dos modelos não são implantados devido a ineficiências de processo. Ao aproveitar pipelines automatizados de CI/CD/CT (treinamento contínuo), os tempos de implantação diminuem de meses para apenas alguns dias. Esses pipelines podem treinar modelos automaticamente quando as métricas de desempenho ficam abaixo dos limites definidos ou quando novos dados ficam disponíveis, eliminando a necessidade de supervisão manual constante.
Os benefícios financeiros são claros. Entre 2022 e 2024, os custos de inferência de IA caíram 280 vezes, tornando o monitoramento contínuo e a reciclagem uma opção prática. Pipelines automatizados também ajudam a detectar problemas antecipadamente, evitando erros dispendiosos. Por exemplo, a má qualidade dos dados pode custar às empresas 12,9 milhões de dólares anualmente, enquanto o tempo de inatividade não planeado do sistema pode atingir os 125.000 dólares por hora. Etapas automatizadas de validação de dados, como identificação de incompatibilidades de esquema, valores nulos ou mudanças de distribuição, garantem que os problemas sejam resolvidos no estágio de ingestão, evitando problemas maiores no futuro.
A automação não apenas acelera os fluxos de trabalho, mas também reduz despesas desnecessárias. Pipelines autoajustáveis garantem que o retreinamento aconteça somente quando necessário, reduzindo o uso de recursos caros de GPU durante períodos ociosos. Ferramentas como o LLM-as-a-Judge simplificam os processos de avaliação, reduzindo custos e mantendo mais de 80% de consistência em milhares de testes.
As estratégias de teste podem otimizar ainda mais os orçamentos. A simulação de testes com ferramentas como Dev Proxy permite testar endpoints sem incorrer em taxas por chamada. Começar com modelos menores e conjuntos de dados representativos ajuda a validar ideias antes de se comprometer com avaliações em grande escala. Além disso, marcar recursos de nuvem por projeto, equipe ou versão de modelo fornece insights detalhados de faturamento, facilitando a decisão de quais fluxos de trabalho valem o investimento.
Os testes automatizados também reforçam a governança, criando as trilhas de auditoria exigidas pelos reguladores. As portas de governança garantem uma pausa nos fluxos de trabalho até que ativos críticos, como esquemas e dados de linha de base, sejam validados. Cada snapshot do modelo passa por uma avaliação de risco padrão, com resultados registrados automaticamente e tickets acionados por falhas emitidos para rastreamento.
A automação pode monitorar três tipos principais de desvio: desvio de dados (mudanças nas distribuições de insumos), desvio de desempenho (declínio na precisão ou tempos de resposta mais lentos) e desvio de segurança (aumento da toxicidade ou exposição de informações sensíveis). Os alertas sinalizam esses problemas antecipadamente, evitando que afetem os usuários finais. Além disso, os kill switches permitem que as equipes desabilitem rapidamente rotas ou recursos de modelos problemáticos durante incidentes, demonstrando uma abordagem prática de governança que garante que os sistemas permaneçam sob controle quando for mais importante.
Os planos pré-pagos são uma maneira inteligente de gerenciar despesas de IA, ao mesmo tempo que permitem que as equipes cresçam e se adaptem sem esforço. Esses planos baseiam-se em estratégias como rastreamento de custos e escalabilidade modular para garantir que os recursos sejam usados de forma eficiente.
With pay-as-you-go pricing, you’re only charged for the tokens and compute time you actually use. Real-time dashboards provide insights into token consumption, latencies, and outcomes, helping to pinpoint inefficiencies and eliminate unnecessary spending. When combined with scale-to-zero capabilities, this model becomes even more effective - idle inference endpoints automatically shut down, so you’re not paying for unused GPU resources.
For tasks that aren’t time-sensitive, such as exploratory data analysis or offline model training, spot pricing offers a lower-cost alternative to on-demand rates. These savings add up, especially when paired with tools that track usage and performance in real time, allowing teams to fine-tune their compute needs and stay within budget.
Elastic compute ensures that your workflows can adapt to changing demands without manual adjustments. Features like autoscaling node pools and serverless architectures handle fluctuating workloads seamlessly, so there’s no need to overprovision resources for peak usage. By separating model artifacts from application code and using cloud storage, pods can start up almost instantly, making scaling operations faster and more efficient.
This approach is particularly valuable when transitioning from pilot projects to full-scale production. As the global MLOps market grows - expected to rise from $1.58 billion in 2024 to $2.33 billion by 2025 - organizations need scalable systems that won’t require constant rebuilding. Pay-as-you-go plans align costs with actual usage, making it easier to expand models, users, or teams without driving up expenses.
Os planos pré-pagos trabalham em conjunto com ferramentas avançadas de equipe para agilizar o gerenciamento de custos e os fluxos de trabalho operacionais. Ferramentas modernas integram governança, trilhas de auditoria e recursos de segurança como logon único (SSO) e controle de acesso baseado em função (RBAC) diretamente na camada de orquestração. Esses recursos são essenciais para atender aos requisitos de conformidade, como SOC 2 ou ISO 27001.
As plataformas que oferecem suporte para APIs compatíveis com OpenAI permitem que as equipes alternem entre provedores ou modelos LLM sem revisar seus fluxos de trabalho, garantindo flexibilidade à medida que novas tecnologias surgem. Os ambientes gerenciados aprimoram ainda mais as operações da equipe ao incorporar recursos como permissões, SLAs, rastreamento centralizado de metadados e controles de autorização. Esses sistemas não apenas são dimensionados junto com a sua organização, mas também mantêm a transparência e o controle necessários para atender aos padrões regulatórios, garantindo que cada membro da equipe tenha o acesso correto e que cada ação seja registrada para auditoria.
A construção de fluxos de trabalho de IA eficazes requer modelos poderosos combinados com uma abordagem estruturada e escalonável. As sete práticas discutidas anteriormente ajudam a transformar iniciativas desarticuladas de IA em processos simplificados e prontos para empresas. Ao incorporar diversos LLMs, manter o monitoramento contínuo de custos e aproveitar designs modulares, você pode remover gargalos e criar fluxos de trabalho que evoluem de acordo com suas necessidades. Começar pela governança garante que cada decisão de IA seja rastreável e compatível, enquanto as solicitações orientadas pela comunidade e os ciclos de testes automatizados aceleram o desenvolvimento sem comprometer a qualidade. Estas estratégias constituem a espinha dorsal de operações de IA eficientes e confiáveis.
Conforme destacado anteriormente, esses métodos podem melhorar a eficiência em 20% a 50% em fluxos de trabalho como integração e gerenciamento de incidentes. O rastreamento de custos em tempo real, combinado com modelos de pagamento conforme o uso, mantém as despesas alinhadas com o uso, evitando estouros de orçamento e ao mesmo tempo apoiando o escalonamento contínuo. Ao integrar ciclos de automação e feedback, os sistemas de IA podem se auto-otimizar, identificando anomalias, sugerindo refinamentos e gerenciando de forma autônoma tarefas complexas.
A mudança em direção à governança integrada e às arquiteturas adaptativas ressalta a importância de construir fluxos de trabalho sobre bases sólidas. Ferramentas padronizadas, limites claros de componentes e rastreamentos detalhados garantem que seus sistemas permaneçam flexíveis à medida que novos modelos e recursos surgem. Ao focar em processos escaláveis e repetíveis, você pode fazer a transição de projetos piloto para produção em grande escala sem revisões constantes.
Juntas, essas estratégias transformam experimentos fragmentados em fluxos de trabalho eficientes, responsáveis e conscientes dos custos. Pronto para assumir o controle de seus fluxos de trabalho de IA? Com Prompts.ai, você pode proteger seus modelos, gerenciar custos e escalar sem esforço. Acesse mais de 35 modelos importantes, utilize controles FinOps integrados e implemente governança de nível empresarial - tudo em uma única interface. Prompts.ai elimina a dispersão de ferramentas, garante a conformidade e permite que sua equipe se concentre na inovação, transformando o caos da IA em uma operação simplificada e orientada para o ROI.
Para escolher o modelo de linguagem grande (LLM) mais adequado, comece identificando claramente suas necessidades específicas - seja para escrita, codificação, suporte ao cliente ou outro aplicativo. Avalie modelos usando uma abordagem estruturada que considera fatores como desempenho, custo e privacidade. Para tarefas com risco mínimo, priorize modelos mais rápidos e mais econômicos. Por outro lado, tarefas de alto risco exigem modelos mais confiáveis e que incluam supervisão adequada. O benchmarking é uma etapa crítica para garantir que o modelo escolhido atenda aos requisitos da tarefa e aos objetivos operacionais.
Para manter os custos da IA sob controle, é essencial monitorar uso de token como isso acontece. Isso envolve rastrear solicitações, prompts e chamadas de modelo. Ao ficar atento a essas métricas, você pode detectar ineficiências e fazer ajustes para otimizar o uso de recursos, mantendo um equilíbrio entre custo e desempenho.
Para ficar à frente dos desvios do modelo, configure sistemas de monitoramento automatizados que monitorem de perto as métricas de desempenho e a qualidade dos dados em tempo real. Essas ferramentas podem detectar mudanças como desvio de conceito, mudança de covariável ou desvio de rótulo, examinando mudanças na distribuição de dados e na precisão da previsão. Quando o desvio é detectado, gatilhos de retreinamento predefinidos podem ser acionados para atualizar seus modelos rapidamente, mantendo uma validação consistente e uma integração suave em seus processos de MLOps.



















