사용한 만큼 지불 - AI Model Orchestration and Workflows Platform

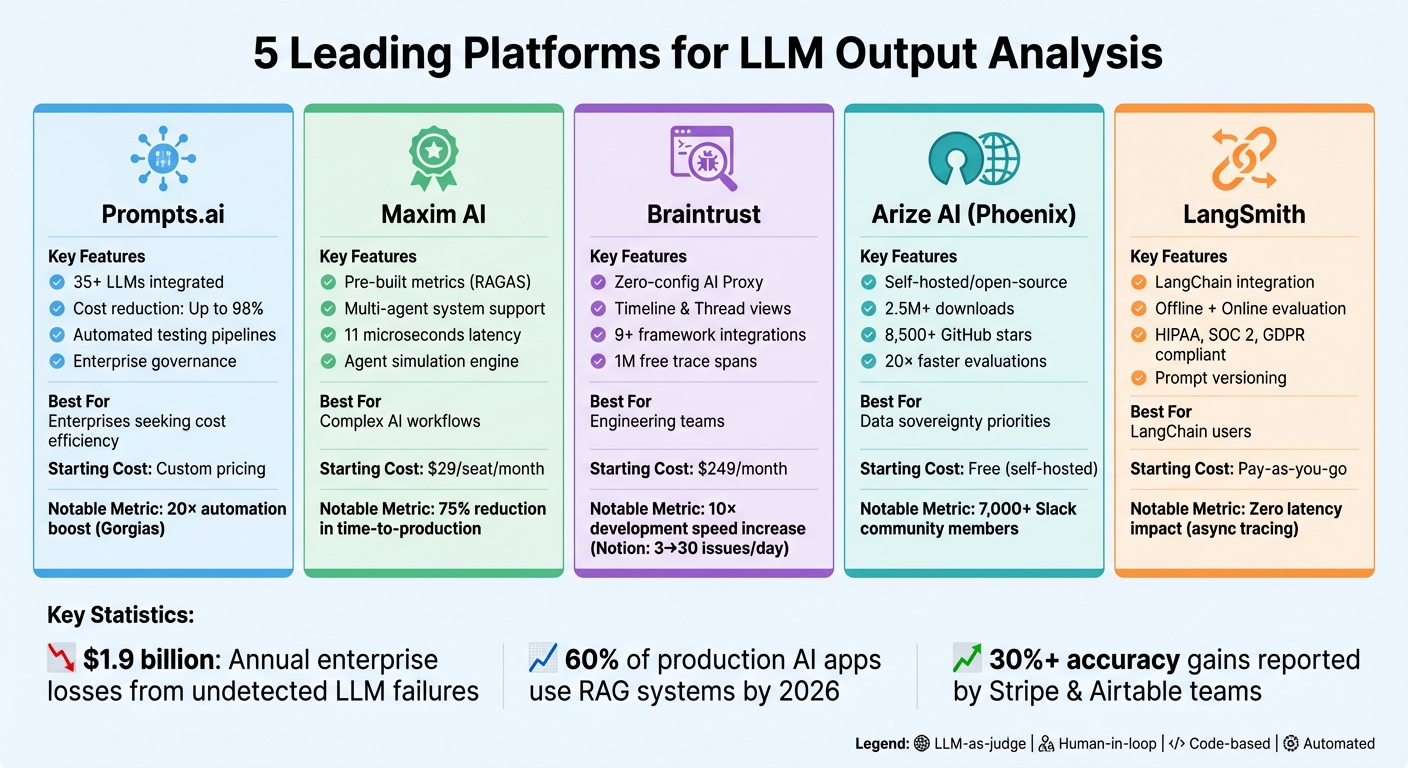
LLM(대형 언어 모델)은 강력하지만 예측할 수 없으며 일관성이 없거나 비용이 많이 드는 결과를 생성하는 경우가 많습니다. 이러한 문제를 해결하기 위해 조직은 평가, 모니터링 및 비용 관리를 위한 전문 도구에 의존합니다. 이 기사에서는 다음을 소개합니다. 다섯 가지 플랫폼 LLM 결과 분석을 간소화합니다.
각 플랫폼은 정확성 향상부터 비용 절감, 규정 준수 보장까지 LLM 워크플로의 고유한 측면을 다룹니다.
| 플랫폼 | 주요 특징 | 최고의 대상 | 시작 비용 |
|---|---|---|---|
| 프롬프트.ai | 중앙 집중식 LLM 액세스, 비용 절감 FinOps 도구 | 비용 효율성을 추구하는 기업 | 맞춤형 가격 |
| 맥심 AI | 사전 구축된 측정항목, 다중 에이전트 시스템 지원 | 복잡한 AI 워크플로우를 관리하는 팀 | $29/사용자당/월 |
| 브레인트러스트 | 디버깅 도구, 다중 회전 대화 테스트 | 엔지니어링 팀 | $249/월 |
| 아리이즈 AI | 오픈소스, 상세한 추적, 환각 검사 | 데이터 관리를 우선시하는 조직 | 무료(자체 호스팅) |
| 랭스미스 | LangChain 통합, 신속한 버전 관리 | LangChain 사용자 | 종량제 |
이러한 플랫폼은 LLM 관리를 단순화하여 확장 가능하고 안정적이며 비용 효율적인 AI 운영을 보장합니다.
__XLATE_5__
Prompts.ai brings together 35+ top-tier LLMs - including GPT‑5, Claude, LLaMA, and Gemini - into one unified platform designed for enterprise-level prompt engineering and detailed output analysis. It simplifies evaluation with automated testing pipelines.
Prompts.ai는 프롬프트 데이터세트에 대해 20개 이상의 테스트를 실행할 수 있는 평가 파이프라인을 갖추고 있습니다. 여기에는 LLM 어설션(AI를 사용하여 출력 등급 지정), 코사인 유사성을 통한 의미론적 유사성 검사, 정확한 일치 평가, 정규식 기반 패턴 일치와 같은 방법이 포함됩니다. 또한 팀은 사용자 친화적인 대시보드를 통해 인간 참여형 평가를 통합할 수 있으므로 도메인 전문가가 인간 피드백을 통한 강화 학습의 일부로 출력을 수동으로 평가할 수 있습니다.
For instance, Gorgias, a customer support platform, used Prompts.ai to scale its AI-powered helpdesk to support millions of shoppers. This led to a 20× boost in automation. Their ML engineers and support teams run daily regression tests on backtest datasets to catch potential issues before deployment.
이러한 엄격한 테스트 기능을 통해 현재 작업 흐름에 원활하게 통합됩니다.
Prompts.ai’s evaluation pipelines seamlessly integrate with CI/CD workflows and enable backtesting against historical production data. The platform supports connections through external HTTP endpoints, custom Python/JavaScript scripts, and Model Context Protocol (MCP) actions.
언어 학습 앱인 Speak는 이러한 자동화 기능을 활용하여 수개월 간의 커리큘럼 개발을 단 1주로 단축했습니다. 이러한 효율성을 통해 그들은 동시에 10개의 새로운 시장에서 AI 기반 기능을 출시할 수 있었습니다.
Prompts.ai는 또한 단계별 모델 비교 보기를 제공하여 팀이 비용을 최적화하는 데 도움을 줍니다. 이러한 비교를 통해 사용자는 API 비용, 대기 시간 및 품질 점수 간의 균형을 가늠할 수 있습니다. 팀은 출력을 요약하거나 중간 작업에 더 작고 빠른 모델을 사용하여 토큰 사용량을 줄일 수 있습니다. 미국 학군의 60%에 서비스를 제공하는 NoRedInk는 이러한 비용 절감 기능을 사용하여 교사 수준의 품질을 유지하면서 백만 명 이상의 학생 성적에 대해 AI 생성 피드백을 제공합니다.
Prompts.ai는 모든 이해관계자에게 LLM 결과를 개선할 수 있는 도구를 제공하여 협업을 강화합니다. 코드가 없는 시각적 편집기를 사용하면 기술 지식이 없는 사용자도 엔지니어의 도움 없이 프롬프트를 편집하고 테스트할 수 있습니다. 중앙 집중식 프롬프트 레지스트리는 효율적인 버전 관리를 보장합니다.
예를 들어 ParentLab은 비기술 분야 전문가가 700개의 즉각적인 개정을 관리할 수 있도록 지원함으로써 단 6개월 만에 400시간 이상의 엔지니어링 시간을 절약했습니다.
__XLATE_12____XLATE_13__
또한 플랫폼은 사용자 평가를 수집하고 이를 성능 점수로 변환하여 지속적인 피드백 루프를 생성하여 모든 통합 모델의 출력 품질을 향상시킵니다.
Maxim AI는 복잡한 AI 워크플로우를 관리하는 팀을 지원하기 위해 기계 중심 평가와 인간 피드백을 혼합하여 심층적인 테스트 및 모니터링 도구를 제공합니다. 그 기능은 강력한 LLM 성과를 유지하는 데 중요한 철저한 평가를 보장하도록 설계되었습니다.
Maxim AI는 결정론적 테스트, 통계적 방법 및 자동화된 판단 도구를 포함하는 강력한 평가 프레임워크를 사용합니다. 그만큼 평가자 저장소 검색 증강 생성 시스템에 맞게 조정된 RAGAS와 같은 사전 구축된 측정항목을 제공합니다. 이는 2026년까지 프로덕션 AI 애플리케이션의 약 60%에 사용되는 핵심 구성 요소입니다. 또한 노드 수준 측정항목 help identify failures in retrieval and generation processes. The platform’s 에이전트 시뮬레이션 엔진을 사용하면 배포 전 평가를 위한 다중 대화 테스트 및 사용자 페르소나 생성이 가능합니다. Clinc 및 Mindtickle과 같은 회사는 이러한 품질 표준을 채택함으로써 생산 시간이 75% 단축되었다고 보고했습니다.
Maxim AI’s evaluation tools integrate effortlessly with today’s development environments. It supports SDKs in Python, TypeScript, Java, and Go, while offering compatibility with platforms like LangChain, LangGraph, Crew AI, OpenAI, Anthropic, Mistral, and AWS Bedrock. The platform also adheres to 오픈텔레메트리 분산 추적 표준을 준수하고 실시간 경고를 위해 Slack 및 PagerDuty와 같은 도구와 연결됩니다. 기업 사용자는 SOC2, HIPAA 및 GDPR 규정 준수 요구 사항을 모두 충족하는 클라우드 및 VPC 내 호스팅을 포함하는 배포 옵션의 이점을 누릴 수 있습니다.
그만큼 Bifrost LLM 게이트웨이 의미론적 캐싱을 사용하여 비용을 줄이는 동시에 토큰 사용 및 API 비용을 모니터링하여 비용이 많이 드는 워크플로를 식별하고 해결합니다. 이는 생산 규모에 따라 효율적인 운영을 보장합니다.
Maxim AI’s 코드 없는 UI 제품 관리자와 디자이너가 프롬프트를 실험하고 독립적으로 평가를 수행할 수 있도록 지원합니다. Rise Science의 제품 책임자인 Kellie Maloney는 다음과 같이 말했습니다.
__XLATE_29__
플랫폼에는 인간 참여형(Human-In-The-Loop) 검토를 위한 주석 대기열, 버전 제어 기능이 있는 중앙 집중식 프롬프트 CMS, SAML/SSO 지원 기능이 있는 RBAC도 포함되어 있습니다. 이러한 협업 도구를 활용하는 팀은 배송 속도가 5배 증가하고 반복 작업이 간소화되며 생산 출시 속도가 빨라졌습니다.
Braintrust는 오프라인 실험과 온라인 채점을 결합하여 팀이 개발부터 배포까지 LLM 성과를 전체적으로 볼 수 있도록 합니다.
Braintrust는 0에서 1까지의 범위에서 출력 품질을 평가하는 다양한 방법을 제공합니다. 팀은 사실성 및 유사성 확인과 같은 작업에 자동 채점기를 사용하거나, LLM을 심사위원으로 평가하거나, 특정 요구 사항에 맞는 사용자 정의 코드 논리를 구현할 수 있습니다. 플랫폼에는 다음이 포함됩니다. 타임라인 보기 Gantt 차트를 사용하여 병목 현상을 식별하고, 스레드 보기 멀티 턴 대화 디버깅 및 샌드박스 React 구성 요소로 표시되는 자연어 기반 추적 시각화를 위한 것입니다. 또한 각 입력에 대해 여러 번의 시험 실행을 지원하여 팀이 차이를 측정하고 일관성을 유지하는 데 도움이 됩니다.
Braintrust는 주요 AI 프레임워크와 원활하게 통합되어 다음을 위한 기본 지원을 제공합니다. 9개 이상의 주요 프레임워크OpenTelemetry, Vercel AI SDK, OpenAI Agent SDK, Instructor, LangChain, LangGraph, Google ADK, Mastra 및 Pydantic AI 등이 있습니다. "랩"을 사용합니다. 통합을 위한 접근 방식 - 예는 다음과 같습니다. 랩AISDK Vercel AI SDK(v3~v6 베타 버전 포함) 및 Wrap_openai 강사용. 플랫폼은 다음을 준수합니다. OpenTelemetry GenAI 의미 체계 규칙, 토큰 사용 및 모델 식별자와 같은 세부 정보를 Braintrust 필드에 자동으로 매핑합니다. OpenAI, Anthropic 및 Google Gemini를 포함한 주요 LLM 제공업체와 원활하게 작동합니다. 개발자는 다음을 사용할 수도 있습니다. 평가() 함수 또는 CLI를 사용하여 --보다 개발 중에 파일이 업데이트될 때마다 자동으로 평가를 다시 실행하는 플래그입니다.
Braintrust는 내장된 도구를 사용하여 팀 협업을 촉진하여 평가 그 이상을 제공합니다. 그것은 양방향 동기화 제품 관리자와 엔지니어가 코드와 UI 간에 프롬프트를 교환하면서 작업할 수 있도록 합니다. 그만큼 운동장 팀이 프롬프트를 테스트하고, 모델을 나란히 비교하고, 빠른 반복을 위해 구성을 공유할 수 있는 코드 없는 공간을 제공합니다. 전용 주석 도구를 사용하면 팀은 인간이 직접 피드백을 제공하고 추적 및 모델 출력에 직접 레이블이나 수정 사항을 추가할 수 있습니다. 외부 주석자를 초대하여 다양한 모델 버전의 품질을 평가할 수 있으며, 공유된 평가 백로그는 데이터세트와 채점 기준표를 중앙 집중화하여 수동 스프레드시트 추적이 필요하지 않습니다.
Arize AI의 Phoenix는 팀이 대규모 언어 모델(LLM) 평가를 포괄적으로 제어할 수 있도록 설계된 오픈 소스 플랫폼입니다. OpenTelemetry를 핵심으로 구축된 Phoenix는 250만 회 이상의 다운로드와 8,500개 이상의 GitHub 스타로 주목을 받았습니다. LLM 워크플로의 모든 단계를 추적하는 자세한 추적 기능을 제공하므로 문제가 발생하는 위치를 더 쉽게 식별할 수 있습니다.
피닉스는 LLM 판사 OpenAI, Anthropic 및 Gemini의 기본 모델을 사용하여 관련성, 독성 및 전반적인 성능과 같은 요소에 대해 다른 LLM 응용 프로그램을 평가합니다. RAG(Retrieval-Augmented Generation) 및 함수 호출과 같은 일반적인 작업을 위해 사전 구축된 평가기가 함께 제공됩니다. 눈에 띄는 특징은 바로 설명능력에서는 평가 모델이 점수에 대한 명확한 추론을 제공하여 개발자가 각 평가의 논리를 이해하는 데 도움을 줍니다. 추가 도구에는 결정론적 코드 기반 검사, 인터페이스 내에서 직접 사람이 주석을 추가하는 기능이 포함됩니다. 데이터 세트 클러스터링 임베딩을 사용하여 의미상 유사한 질문과 응답을 시각적으로 그룹화합니다. 이 클러스터링은 모델의 성능이 저조한 영역을 격리하는 데 도움이 됩니다.
__XLATE_63__
이러한 평가 도구는 플랫폼의 광범위한 개발 생태계와 원활하게 통합됩니다.
Phoenix는 LlamaIndex, LangChain, DSPy, Mastra 및 Vercel AI SDK와 같은 널리 사용되는 프레임워크에 대한 자동 계측을 지원합니다. Python, TypeScript 및 Java와 함께 작동하며 OpenTelemetry 기본 디자인은 사용자를 특정 공급업체에 가두지 않고 기존 관찰 도구와의 호환성을 보장합니다. 또한 팀은 Ragas, Deepeval 또는 Cleanlab과 같은 타사 라이브러리의 평가를 통합하여 워크플로 전반에 유연성을 제공할 수 있습니다.
Phoenix는 효율성을 위해 제작되었습니다. 최대 20배 빠른 평가 실행 동시성과 일괄 처리를 통해. Prompt Playground는 팀이 배포 전에 프롬프트를 개선하고 모델 변형을 나란히 비교할 수 있는 테스트 환경을 제공하여 비용이 많이 드는 생산 실수의 위험을 줄입니다.
완전한 오픈 소스이자 자체 호스팅 가능한 플랫폼인 Phoenix는 팀이 데이터를 완벽하게 제어할 수 있도록 보장합니다. 다음과 같은 기능 사람 주석 대기열 Ground Truth 라벨을 추적에 직접 추가하여 더 나은 협업을 촉진할 수 있습니다. 그만큼 프롬프트 허브 환경 전반에 걸쳐 신속한 버전 관리, 저장 및 배포를 관리하는 동시에 스팬채팅 도구를 사용하면 팀에서 특정 워크플로 세그먼트를 평가하고 논의하여 성능 문제를 찾아낼 수 있습니다. 7,000명이 넘는 회원으로 구성된 Slack 커뮤니티를 통해 사용자는 네트워크에 액세스하여 문제를 해결하고 통찰력을 공유할 수 있습니다.
__XLATE_76__
LangSmith는 LangChain 유무에 관계없이 원활하게 작동하도록 설계된 다목적 플랫폼으로, 모든 LLM 스택에 적용할 수 있습니다. OpenAI, Anthropic, CrewAI, Vercel AI SDK, Pydantic AI와 같은 도구와 쉽게 연결되어 이미 특정 프레임워크를 사용하고 있는 팀에 유연성을 제공합니다. 플랫폼은 HIPAA, SOC 2 Type 2, GDPR과 같은 규정 준수 표준을 충족하고 비동기 프로세스를 사용하여 추적을 전송하므로 최종 사용자에게 추가 대기 시간이 발생하지 않습니다.
LangSmith가 제공하는 두 가지 평가 모드 다양한 요구 사항에 맞게 개발 중 선별된 데이터 세트를 테스트하기 위한 오프라인 평가와 실시간 프로덕션 트래픽을 모니터링하기 위한 온라인 평가. 네 가지 유형의 평가기를 지원합니다.
플랫폼에는 다음과 같은 고급 분석 도구가 포함되어 있습니다. 차이점 보기, 모델 출력과 참조 텍스트 간의 차이점을 강조하고 성능 벤치마킹을 위한 병렬 비교를 제공합니다. 그것은 또한 제공합니다 메타데이터 그룹화, 주제 영역이나 사용자 유형과 같은 범주별로 정확성이나 비용과 같은 지표를 분석할 수 있습니다. LangSmith는 오픈 소스와 통합됩니다. 공개 평가 패키지는 정확성과 간결성을 평가하기 위해 사전 구축된 평가기를 제공합니다.
이러한 기능을 사용하면 LangSmith를 기존 작업 흐름 및 개발 도구에 쉽게 통합할 수 있습니다.
LangSmith는 다음을 사용하여 추적을 단순화합니다. @추적 가능 입력과 출력을 자동으로 캡처하는 데코레이터 또는 클라이언트 래퍼. Python 및 TypeScript/JavaScript SDK, REST API, pytest, Vitest, Jest와 같은 테스트 프레임워크와의 통합을 지원하므로 CI/CD 파이프라인에 평가를 쉽게 포함할 수 있습니다. 또한 OpenTelemetry 통합을 통해 팀은 기존 관찰 파이프라인에서 LangSmith로 직접 추적을 보낼 수 있습니다.
LangSmith는 직관적인 피드백과 주석 도구를 통해 팀 협업을 강화합니다. 주석 대기열 사용자 정의 기준에 따른 수동 검토 및 점수 매기기를 위해 특정 실행을 해당 분야 전문가에게 자동으로 라우팅할 수 있습니다. 그만큼 프롬프트 허브 팀이 프롬프트를 반복하고, 버전을 지정하고, 공유할 수 있는 중앙 집중식 공간으로 사용되며, 개발 전반에 걸쳐 일관성을 유지하기 위한 변경 사항 추적 및 롤백 기능이 완비되어 있습니다. 인라인 주석 기능을 통해 팀 구성원은 문제를 표시하거나 응답 품질에 대한 목표 피드백을 제공하여 평가 정확성과 작업 흐름 효율성을 모두 향상시킬 수 있습니다.
또한 이 플랫폼은 상세한 사용자 관리 및 워크로드 격리를 제공하여 팀 간의 원활한 협업을 보장합니다. 사용자는 smith.langchain.com에서 무료로 가입할 수 있습니다. 신용카드는 필요하지 않습니다. 프로덕션 용도의 경우 LangSmith는 AWS, GCP 또는 Azure 전반의 Kubernetes 클러스터에서 자체 호스팅이 가능한 엔터프라이즈 계획을 통해 종량제 방식으로 운영됩니다.
LLM 평가를 위한 플랫폼을 평가할 때 기술 호환성, 비용 및 평가 방법을 고려하는 것이 중요합니다. 옵션을 자세히 살펴보면 다음과 같습니다.
프롬프트.ai 35개 이상의 주요 모델을 하나의 보안 인터페이스에 통합하여 AI 소프트웨어 비용을 최대 98%까지 절감할 수 있는 FinOps 제어 기능을 제공합니다. 브레인트러스트 구성이 필요 없는 AI 프록시로 설정을 단순화하고 단일 기본 URL을 통해 로그를 캡처합니다. 1백만 개의 추적 범위가 무료로 포함되어 있으며 유료 요금제는 월 $249부터 시작합니다. 맥심 AI 전체 추적에 대한 품질 채점에 중점을 두고 기존 관측 가능성 스택과 원활하게 통합됩니다. 월 최대 10,000개의 로그에 대한 무료 플랜과 시트당 월 29달러부터 시작하는 유료 플랜을 제공합니다. 아리즈 피닉스 데이터 개인 정보 보호를 위한 자체 호스팅을 지원하고 RAGAS 및 Giskard와 같은 도구를 통합하여 더 심층적인 지표 분석을 수행합니다. 랭스미스 기업 지원 가격은 다양하지만 LangChain 사용자를 위해 맞춤화되어 고급 관찰 가능성을 제공합니다. 특히 Notion은 Braintrust를 통해 개발 속도를 매일 3개 문제에서 30개로 증가시켜 10배 향상시켰습니다.
각 플랫폼의 고유한 접근 방식은 특정 평가 요구 사항에 따라 의사 결정을 단순화합니다. 평가 방법, 통합 및 배포 측면에서 비교하는 방법은 다음과 같습니다.
통합 복잡성도 중요한 역할을 합니다. Braintrust의 프록시 기반 설정은 간단합니다. API 기본 URL을 업데이트하기만 하면 됩니다. Maxim AI는 기존 관측 가능성 도구와 통합되는 반면 LangSmith의 긴밀한 LangChain 통합은 특수한 관측 가능성 요구 사항을 충족합니다. Arize Phoenix는 자체 호스팅 오픈 소스 솔루션을 제공하여 데이터 주권을 우선시하는 조직에서 두각을 나타냅니다. 한편 Prompts.ai는 안전한 운영을 위해 엔터프라이즈급 거버넌스 제어와 완전한 감사 추적을 제공합니다.
__XLATE_111__
신속한 통찰력을 얻기 위해 프록시 기반 배포와 심층 통합을 통해 프로세스를 간소화합니다. LangChain 사용자는 LangSmith가 자연스럽게 적합하다는 것을 알게 될 것이며 민감한 데이터를 관리하는 조직은 강력한 거버넌스 및 감사 기능을 위해 Arize Phoenix 또는 Prompts.ai와 같은 오픈 소스 솔루션에 의지할 수 있습니다.
제공된 평가를 기반으로 각 플랫폼은 LLM 결과 분석을 개선하는 데 있어 뚜렷한 이점을 제공합니다. 프롬프트.ai 강력한 거버넌스 및 감사 기능을 보장하는 동시에 AI 비용을 최대 98%까지 줄일 수 있는 FinOps 제어 기능과 결합하여 기업에 주요 모델에 대한 중앙 집중식 액세스를 제공합니다. 브레인트러스트 Notion과 같은 회사는 개발 속도가 10배 증가하여 하루 3건에서 30건으로 문제 해결 속도가 향상되었다고 보고하는 등 빠르게 진행되는 엔지니어링 팀에 맞게 조정되었습니다. 마찬가지로 Stripe 및 Airtable 팀은 플랫폼을 채택한 지 몇 주 만에 정확도가 30% 이상 향상되는 것을 확인했습니다.
LangChain 생태계에 깊이 통합된 사람들을 위해, 랭스미스 손쉬운 통합과 빠른 프로토타이핑 옵션을 제공합니다. 맥심 AI 복잡한 다중 에이전트 시스템 관리에 중점을 두는 팀에 적합하며, 초당 5,000건의 요청 볼륨에서 단 11마이크로초의 오버헤드를 발생시키는 정밀한 채점 도구와 지연 시간이 짧은 게이트웨이를 제공합니다. 그 동안에, 아리즈 피닉스 데이터 주권을 우선시하는 조직에 이상적이며 기존 관찰 시스템에 완벽하게 맞는 자체 호스팅 오픈 소스 솔루션을 제공합니다.
각 플랫폼은 LLM 성과 및 비용 관리의 중요한 과제를 해결합니다. 기업이 잠재적인 손실에 직면한 상황에서 연간 19억 달러 프로덕션에서 발견되지 않은 LLM 실패로 인해 주관적인 평가를 넘어 측정 가능한 데이터 기반 지표로 전환해야 하는 필요성이 신뢰성과 효율성을 보장하는 데 필수적이 되었습니다.
이러한 도구는 LLM 개발을 구조화된 엔지니어링 분야로 승격시킵니다. 매달 수조 건의 이벤트를 처리하는 것, 팀 간 공동 작업을 간소화하는 것, 자체 호스팅 인프라에 대한 제어를 유지하는 것 등 어떤 것에 중점을 두더라도 올바른 플랫폼을 선택하면 LLM 워크플로가 목표를 달성하는 데 필요한 안정성, 품질 및 비용 효율성을 달성할 수 있습니다.
이러한 플랫폼은 대규모 언어 모델(LLM) 사용을 모니터링하고 세부 조정하는 도구를 제공하여 조직이 AI 비용을 절감할 수 있도록 설계되었습니다. 예를 들어 Prompts.ai와 같은 솔루션을 사용하면 사용자가 실시간으로 토큰 사용을 추적할 수 있어 불필요한 토큰 소비를 더 쉽게 찾아내고 줄일 수 있습니다. 이를 통해 과도한 API 호출에 대한 과도한 지출을 방지하고 비용 관리를 개선할 수 있습니다.
비용 관리 외에도 이러한 플랫폼은 성능 및 출력 품질에 대한 귀중한 통찰력을 제공합니다. 환각이나 오류와 같은 문제를 감지하고 예방하는 데 도움이 될 수 있으며, 그렇지 않으면 비용이 많이 드는 재작업으로 이어질 수 있습니다. 사용 추세를 분석하고 비효율성을 정확히 찾아냄으로써 조직은 워크플로를 간소화하고 운영 비용을 낮추며 일관된 고품질 결과를 보장할 수 있습니다. 이 모든 것이 AI 예산을 효과적으로 관리하기 위한 보다 스마트하고 데이터 중심적인 결정을 지원합니다.
LLM 플랫폼은 도구 및 워크플로와 원활하게 연결하여 다양한 요구 사항을 충족할 수 있는 다양한 방법을 제공합니다. 많은 플랫폼은 LangChain 및 LangServe와 같은 프레임워크와 함께 Python 및 JavaScript와 같은 SDK를 통해 기본 통합을 지원합니다. 이를 통해 LLM을 사용자 정의 애플리케이션에 간단하고 효율적으로 포함할 수 있습니다. 모니터링을 위해 플랫폼은 종종 OpenTelemetry와 같은 개방형 표준을 지원하여 기존 인프라와의 호환성을 보장합니다.
일부 플랫폼은 GitHub Actions 및 Jenkins와 같은 CI/CD 도구와 통합되어 테스트 및 배포 프로세스를 단순화합니다. 환경 제어를 우선시하는 조직의 경우 자체 호스팅 옵션을 사용할 수 있어 데이터 보안을 유지하면서 사용자 정의가 가능합니다. 이러한 통합 기능을 통해 사용자는 효율성을 높이고 성능을 효과적으로 모니터링하며 작업 내에서 LLM을 안전하게 구현할 수 있습니다.
프리미엄을 생각하시는 분들을 위해 데이터 개인 정보 보호 및 제어, 온프레미스.LLM 탁월한 솔루션을 제공합니다. 개인 정보 보호에 민감한 작업을 위해 특별히 설계된 이 플랫폼을 사용하면 LLM(대형 언어 모델)이 오프라인 설정에서 기밀 또는 제한된 데이터를 안전하게 처리할 수 있습니다. 완전한 로컬 실행을 활성화함으로써 데이터 노출 가능성을 크게 줄이는 동시에 필요한 경우 하이브리드 설정을 위한 선택적 클라우드 통합도 제공합니다.
직관적인 노코드 인터페이스를 갖춘 OnPrem.LLM은 기술 전문 지식이 없는 사용자의 접근성을 보장하는 동시에 데이터 관리에 대한 완전한 감독을 유지합니다. 따라서 정보 보호가 최우선 과제인 규제 대상이거나 민감한 산업 분야의 조직에 이상적인 선택입니다.



















