Paiement à l'Usage - AI Model Orchestration and Workflows Platform

AI workflows in 2026 face challenges like fragmented tools, unchecked model drift, and escalating costs. To overcome these, organizations are adopting smarter, automated workflows that unify tools, improve governance, and optimize spending. Here’s how you can transform your AI operations:
Ces pratiques rationalisent les flux de travail, améliorent la surveillance et réduisent les coûts, permettant ainsi aux organisations de faire évoluer l'IA de manière responsable et efficace.
__XLATE_1__
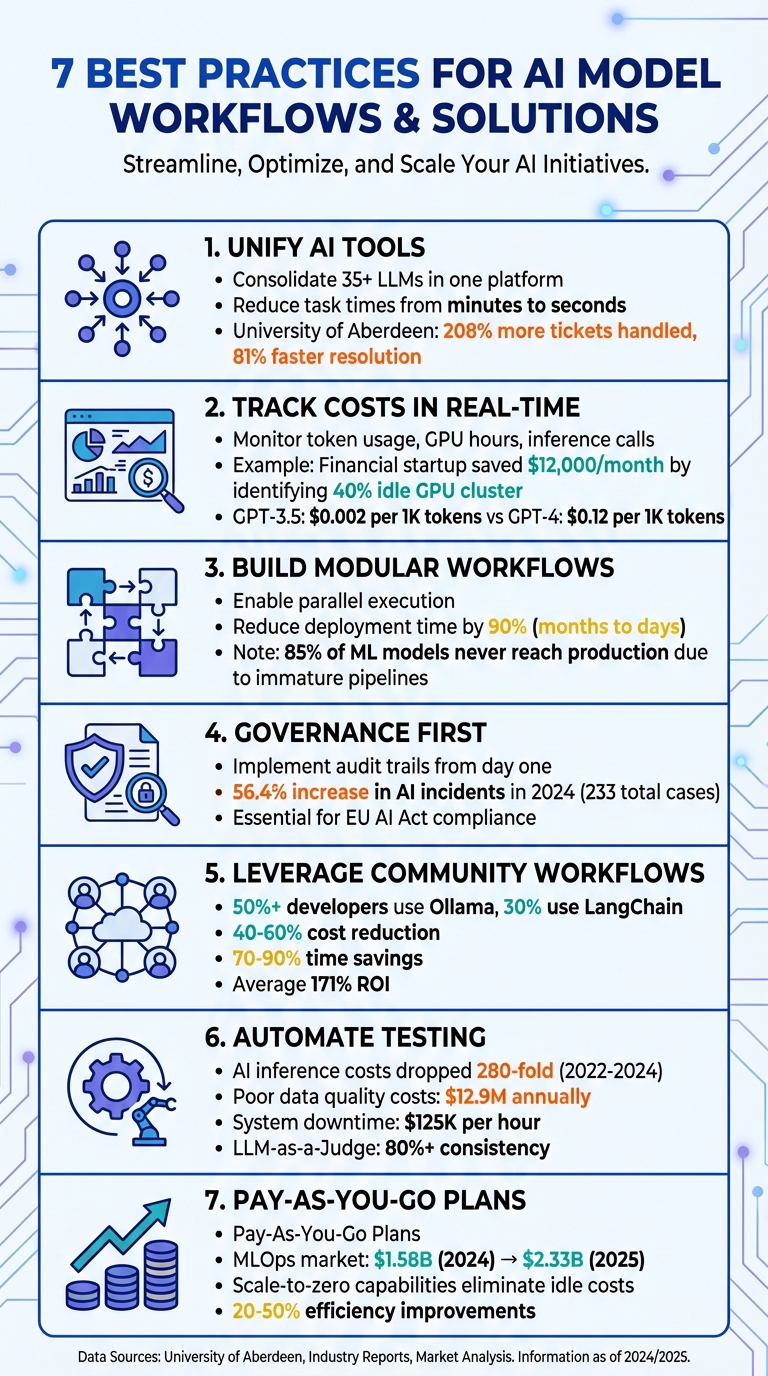
La gestion de plates-formes distinctes pour des modèles tels que GPT-5, Claude, LLaMA et Gemini peut ralentir les opérations et créer des obstacles inutiles. En consolidant plus de 35 LLM dans une seule interface, Prompts.ai élimine les tracas liés à la jonglerie entre plusieurs connexions et informations d'identification, réduisant ainsi la durée des tâches de quelques minutes à quelques secondes seulement.
Ce type d’intégration génère des gains de productivité mesurables. Par exemple, lorsque l'Université d'Aberdeen a adopté un système basé sur l'IA en septembre 2025, son équipe informatique a réussi à traiter 208 % de tickets en plus tout en réduisant les temps de résolution de 81 % [1]. De tels résultats mettent en évidence comment un système rationalisé permet aux équipes de se concentrer sur les résultats plutôt que de perdre du temps à gérer des outils fragmentés. Cette approche ouvre la voie à des flux de travail d’IA plus efficaces, plus fiables et plus rentables.
Une interface unifiée ne permet pas seulement de gagner du temps : elle garantit une plus grande fiabilité et flexibilité. Avec tous les modèles accessibles depuis une plate-forme unique, les équipes peuvent basculer de manière transparente entre les moteurs, garantissant ainsi la continuité même si un modèle échoue ou fournit des résultats inexacts. Cette configuration proactive évite l'emballement des processus, qui peut entraîner une montée en flèche des coûts du cloud lorsque les agents automatisés bouclent sans contrôles appropriés.
La plateforme permet également des tests de performances côte à côte, afin que vous puissiez évaluer quel modèle convient le mieux à des tâches spécifiques. Par exemple, les requêtes du support client peuvent être acheminées vers un LLM, les projets créatifs vers un autre et le traitement des données vers un troisième, le tout géré à partir du même tableau de bord. Cette conception indépendante du modèle garantit que vous n'êtes pas lié aux limitations ou aux prix d'un seul fournisseur, vous donnant ainsi la liberté d'optimiser les performances et les coûts.
Prompts.ai fait passer la gestion des coûts à un niveau supérieur en offrant des informations en temps réel sur l'utilisation des jetons sur tous les modèles. Cette transparence permet d’éviter les dépassements budgétaires avant qu’ils ne surviennent. Une couche FinOps intégrée suit les dépenses au niveau de l'invite, ce qui facilite l'identification des flux de travail qui génèrent de la valeur et de ceux qui drainent des ressources. Les organisations utilisant l'automatisation des flux de travail par l'IA ont signalé un retour sur investissement de 84 % lorsqu'elles peuvent lier les dépenses aux résultats commerciaux. Databricks, par exemple, a réduit les tickets d'assistance de 23 % grâce à un tri intelligent alimenté par des modèles de données propres et un suivi transparent des coûts [1].
Les crédits TOKN payants de la plateforme alignent les dépenses sur l'utilisation réelle, éliminant ainsi le besoin de payer pour la capacité inutilisée. En consolidant les coûts sur plusieurs modèles, les équipes peuvent économiser jusqu'à 98 % par rapport au maintien d'abonnements séparés pour chaque outil, créant ainsi des économies significatives entre les projets et les départements.
Prompts.ai renforce également la gouvernance et la conformité, en offrant des pistes d'audit unifiées qui prennent en charge à la fois les exigences réglementaires et l'amélioration des flux de travail. La plateforme classe les tâches en niveaux de risque, garantissant que les opérations à enjeux élevés (comme les tâches de niveau 4 avec un potentiel catastrophique) restent sous supervision humaine jusqu'à ce que les systèmes d'IA soient pleinement fiables.
Grâce au chiffrement de bout en bout et aux contrôles d’accès stricts, les données sensibles restent protégées contre les erreurs de configuration ou les violations. Alors que 78 % des organisations utilisent désormais l'IA dans au moins un domaine de leur activité [2], Prompts.ai offre une sécurité de niveau entreprise tout en conservant la vitesse et l'agilité dont les équipes ont besoin pour innover. Chaque interaction est sécurisée, traçable et auditable, ce qui donne aux organisations la confiance nécessaire pour faire évoluer l'IA de manière responsable.
Les charges de travail de l'IA entraînent souvent des dépenses imprévisibles qui ne peuvent pas être entièrement comprises via des factures mensuelles. FinOps en temps réel change cela en offrant des informations immédiates sur les coûts au fur et à mesure qu'ils surviennent. En suivant l'utilisation des jetons, les heures GPU et les appels d'inférence en temps quasi réel, les équipes peuvent identifier et résoudre les dépassements de budget avant qu'ils ne deviennent incontrôlables.
Par exemple, une startup d’analyse financière a découvert que 40 % de son cluster de 8 GPU restait inactif, gaspillant près de 12 000 $ chaque mois. Grâce à une surveillance en temps réel, l'équipe a identifié cette inefficacité à mi-sprint et a procédé à des ajustements pour optimiser immédiatement la capacité.
Un suivi granulaire par équipe, projet ou client affine davantage les modèles de rétrofacturation. En attachant des métadonnées telles que les identifiants clients aux requêtes API, les dépenses deviennent plus transparentes. Cela permet aux départements de payer uniquement pour ce qu'ils utilisent, ouvrant ainsi la voie à des opérations à la fois évolutives et rentables.
Real-time tracking doesn’t just monitor costs - it actively supports smarter scaling decisions. Autoscaling can now factor in both performance metrics (like latency) and financial data (such as cost per prediction). For example, during traffic spikes, systems can throttle or reroute requests based on cost signals, ensuring resources are used efficiently.
__XLATE_13__
StreamForge AI a adopté cette stratégie en septembre 2025 en intégrant Kubecost à Prometheus et en affichant les données d'utilisation sur des tableaux de bord Grafana actualisés toutes les cinq minutes. En utilisant une approche de mise à l'échelle automatique à double signal - équilibrant la latence p95 et les mesures de coût par requête - ils ont considérablement augmenté l'utilisation du GPU et amélioré la rentabilité de plus de 300 tâches de formation quotidiennes. Cette approche en temps réel permet d'éviter des erreurs de configuration coûteuses qui pourraient épuiser les budgets mensuels.
Centralizing cost tracking across multiple AI providers is essential when managing diverse models. A unified AI gateway simplifies this process by consolidating token usage, latency, and cost data into a single, reliable source. Whether you’re using OpenAI, Anthropic, or self-hosted models, this centralized system eliminates the need to piece together fragmented billing data.
Ce niveau d’intégration est crucial car les différents modèles ont des prix très différents. Par exemple, GPT-3.5-Turbo coûte environ 0,002 $ pour 1 000 jetons, tandis que GPT-4 peut aller jusqu'à 0,12 $ pour 1 000 jetons selon la fenêtre contextuelle. Le suivi en temps réel permet aux équipes de comparer ces coûts et d'acheminer les tâches vers le modèle le plus économique. Qu'il s'agisse de requêtes clients simples ou d'analyses complexes, les tâches sont attribuées au bon modèle en fonction des données de coûts en direct, garantissant ainsi que les flux de travail restent à la fois efficaces et respectueux du budget.
La décomposition des flux de travail d'IA en composants modulaires révolutionne la façon dont ils sont déployés et mis à l'échelle. Au lieu de s'appuyer sur un pipeline unique et rigide pour gérer chaque étape, une approche modulaire permet de mettre à jour ou de remplacer des pièces individuelles sans perturber l'ensemble du système.
Cette conception permet également une exécution parallèle, dans laquelle plusieurs tâches peuvent s'exécuter en même temps. Par exemple, un service de traduction multilingue peut traiter plusieurs versions linguistiques simultanément plutôt que l’une après l’autre, réduisant ainsi considérablement le temps de traitement. L'adoption des pratiques MLOps accélère encore le déploiement, réduisant ainsi le temps nécessaire à la mise en production d'un modèle jusqu'à 90 %. Les pipelines automatisés peuvent réduire les délais de déploiement de plusieurs mois à quelques jours seulement.
Un autre avantage est la rejouabilité. Si une étape spécifique, telle que le post-traitement, rencontre un problème, vous pouvez réexécuter uniquement ce module en utilisant les artefacts stockés au lieu de refaire l'intégralité du flux de travail. Cette approche de réexécution ciblée permet d'économiser du temps et des ressources, en particulier pour les tâches qui nécessitent une puissance de calcul importante. Les flux de travail modulaires facilitent également la standardisation et l'intégration sécurisée des composants dans l'ensemble du système.
Une fois une base modulaire en place, assurer une communication fluide entre les composants devient essentiel. La normalisation des formats d’entrée et de sortie permet d’éviter les erreurs en cascade. Par exemple, si un module d'ingestion de données génère un fichier JSON clairement défini qui s'aligne parfaitement avec l'entrée attendue d'un module d'inférence, les problèmes de communication potentiels sont éliminés.
Séparer la logique de l’IA de la logique politique améliore encore la maintenabilité. Cela vous permet de gérer le comportement du modèle dynamique indépendamment des règles métier fixes, comme souligné dans AWS Prescriptive Guidance. Des outils comme Docker ou Kubernetes peuvent conteneuriser les modules, garantissant ainsi leur portabilité dans différents environnements. Un module conteneurisé peut fonctionner de manière cohérente en matière de développement, de préparation et de production, et peut même passer d'un fournisseur de cloud à l'autre sans nécessiter de modifications. Pour l'orchestration, AWS Step Functions fournit une coordination sans serveur avec des tentatives intégrées, tandis qu'Apache Airflow offre une flexibilité basée sur Python pour gérer des flux de travail plus complexes.
Les conceptions modulaires apportent également des avantages financiers en vous permettant d'allouer les bonnes ressources pour chaque tâche. Les modèles de raisonnement complexes, gourmands en ressources, peuvent être réservés à des analyses exigeantes, tandis que des tâches plus simples sont traitées par des modèles moins coûteux. Cela garantit que les ressources informatiques sont utilisées judicieusement.
Le suivi des métadonnées au niveau du module améliore la transparence. En attachant des détails tels que des horodatages, des versions de modèle et des données de coût à chaque artefact au fur et à mesure de son évolution dans le pipeline, les équipes bénéficient d'une piste d'audit claire. Cela facilite non seulement le débogage mais également le suivi financier. L'alignement des coûts sur les mesures spécifiques au module permet une budgétisation précise tout en conservant la flexibilité. De plus, la définition de limites sur la taille des lots et la simultanéité peut aider à éviter des dépenses imprévues pendant les périodes de forte demande.
It’s worth noting that about 85% of machine-learning models never make it to production, often due to immature pipeline structures. Modular, iterative workflows offer a way to overcome this challenge. Teams can start small, validate one module at a time, and gradually scale up, reducing risks and ensuring systems are ready for production.
L'intégration de la gouvernance dans votre flux de travail d'IA dès le début vous évite des ajustements coûteux en fin de compte. En vous appuyant sur les évaluations automatisées et la transparence évoquées précédemment, vous pouvez garantir que la conformité est intégrée à vos processus dès le départ. Dès qu'un modèle ou un cas d'utilisation est créé, générer un ticket de suivi dans votre outil de workflow et attribuer un niveau de risque initial. Les applications à haut risque, telles que les systèmes de notation de crédit ou de recrutement, exigent des processus d'approbation plus stricts et une surveillance plus étroite par rapport aux outils à faible risque utilisés en interne. Ce « décalage à gauche » proactif Cette approche vous permet de vous préparer aux exigences réglementaires, en particulier avec des cadres tels que la loi européenne sur l'IA qui impose une documentation détaillée des processus de formation et d'évaluation.
La pierre angulaire de la conformité est suivi de la lignée, qui fournit un chemin clair et reproductible depuis les données brutes jusqu'à la sortie finale du modèle. Combinez le suivi de la lignée avec traçabilité des instantanés, garantissant que l'état exact de votre code, de vos données et de vos configurations est préservé avant le déploiement. Cela vous permet de reproduire n'importe quelle version du modèle selon vos besoins. Les recherches du secteur soulignent l'urgence de ces mesures, notant une augmentation de 56,4 % des incidents liés à l'IA en 2024, totalisant 233 cas, soulignant la nécessité de pistes d'audit solides.
Les pistes d'audit rationalisent le dépannage en reliant directement les erreurs à leurs origines. Au lieu de parcourir manuellement les journaux, les ingénieurs peuvent utiliser le suivi de traçabilité pour identifier rapidement où un pipeline s'est rompu ou où la qualité des données a diminué. L'automatisation des tâches de gouvernance, telles que les contrôles d'actifs et les évaluations des risques, garantit non seulement la conformité, mais permet également à vos initiatives d'IA de progresser efficacement à mesure qu'elles se développent. En automatisant ces étapes, vous pouvez réduire les délais d'approbation et maintenir la cohérence entre les opérations.
Une gouvernance des données solide est essentielle pour maintenir des données de haute qualité. La gestion centralisée des métadonnées consolide les informations sur tous les actifs d'IA en un seul endroit, supprimant les redondances et garantissant le bon fonctionnement. Lorsque chaque composant, des invites aux versions de modèle, est suivi avec des horodatages et des détails de coûts, les équipes bénéficient d'un historique complet de l'exécution. Cela rend les pipelines plus faciles à reproduire et à affiner. Les journaux d'audit automatisés réduisent davantage les erreurs humaines, établissant ainsi un flux de travail fiable et reproductible.
Ces stratégies de gouvernance s'intègrent parfaitement aux flux de travail modulaires, garantissant que la conformité reste un élément essentiel de votre système à mesure qu'il évolue.
Une couche de gouvernance unifiée relie les flux de travail rationalisés et la transparence des coûts, garantissant ainsi la conformité à tous les niveaux. De nombreux systèmes, tels que Snowflake, Databricks, les plateformes cloud et les environnements périphériques, fonctionnent sur plusieurs plateformes. Sans une approche de gouvernance unifiée, vous risquez une « IA fantôme », où les modèles sont déployés sans surveillance, rendant impossible la vérification de la conformité. Traçabilité inter-systèmes garantit que le traçage des données d'exécution est capturé dans les requêtes, les blocs-notes, les tâches et les tableaux de bord, garantissant ainsi la conformité à mesure que les données circulent entre les plates-formes. Des interfaces standardisées, comme le Model Context Protocol (MCP) avec des passerelles centralisées, permettent une journalisation et un suivi des demandes cohérents sur les serveurs et les locataires. Cela vous donne une piste d’audit complète, quel que soit l’endroit où le travail a lieu.
Créer des flux de travail à partir de zéro peut prendre du temps et être inefficace. Les cadres communautaires comme LangChaîne et Ollama sont devenues des solutions incontournables, proposant des modèles prédéfinis pour enchaîner les invites et intégrer des outils. Ces frameworks sont largement adoptés, avec plus de 50 % des développeurs utilisant Ollama et près d'un tiers s'appuyant sur LangChain pour gérer les agents d'IA. Ils remplacent le code personnalisé fragile par des fonctions flexibles et sans serveur qui fonctionnent de manière indépendante, ce qui les rend plus faciles à gérer et à faire évoluer.
Le principal avantage est évolutivité sans complexité. En vous appuyant sur des modèles testés par la communauté, vous pouvez changer de modèle (par exemple passer de GPT à Amazon Bedrock) sans remanier votre logique d'orchestration. Cette flexibilité accélère le déploiement tout en maintenant la cohérence. Les recherches montrent que même si l’orchestration est une priorité pour de nombreuses organisations, seules quelques-unes l’ont pleinement mise en œuvre. Les flux de travail communautaires offrent une solution pratique, permettant une intégration transparente sur diverses plates-formes d'IA.
Les flux de travail communautaires relèvent également le défi de l’intégration des outils d’IA sur toutes les plateformes. Des normes comme la Protocole de contexte de modèle (MCP) s’attaquer au problème de l’étalement des plateformes, une préoccupation pour 63% des cadres. Ces protocoles permettent aux agents et outils d'IA de travailler ensemble sur des plateformes telles que Gmail, Slack et CRM sans nécessiter de saisie manuelle des données. Par exemple, une simple requête en langage naturel, telle que « Résumer les 10 derniers e-mails de Gmail » ; - peut déclencher des tâches structurées avec des connexions API préconfigurées.
__XLATE_52__
L'interopérabilité est essentielle, avec 87 % des responsables informatiques l’identifiant comme essentiel pour l’adoption de systèmes basés sur l’IA. Les flux de travail communautaires sont conçus dans un souci de résilience, offrant des fonctionnalités telles que les tentatives automatisées, les délais d'attente et l'exécution parallèle pour gérer les échecs potentiels du modèle. Ces garanties sont essentielles, d'autant plus que 87 % des développeurs s'inquiètent de la précision de l'IA, et 81 % sont préoccupés par la sécurité et la confidentialité. Au-delà de l’amélioration de l’intégration, ces flux de travail contribuent également à réduire considérablement les coûts.
L’utilisation de modèles communautaires pour transformer les invites en langage naturel en flux de travail automatisés peut réduire considérablement les coûts et gagner du temps. Rapport des organisations 40 à 60 % de réduction des coûts et 70 à 90 % de gain de temps lorsqu'ils adoptent l'automatisation de l'IA via ces flux de travail. Commencer par des solutions testées élimine le besoin de processus coûteux d’essais et d’erreurs.
Ces flux de travail améliorent également la transparence en intégrant des pistes d'audit standardisées et un suivi des métadonnées. Ils enregistrent automatiquement des détails tels que les sources de données, les autorisations et l'historique des décisions des agents. Beaucoup incluent humain dans la boucle des points de contrôle pour l’examen manuel des tâches sensibles ou coûteuses, garantissant ainsi une surveillance là où cela compte le plus. En gérant les coûts d'inférence pendant la mise à l'échelle, les entreprises ont constaté en moyenne 171 % de retour sur investissement lorsque vous exploitez des flux de travail créés par la communauté.
L’automatisation des tests et de l’évaluation est la dernière étape dans la création d’un cycle de vie transparent de l’IA. Il élimine les retards causés par les tests manuels, qui empêchent souvent les modèles d'atteindre la production : 85 % des modèles ne parviennent pas à être déployés en raison d'inefficacités des processus. En tirant parti des pipelines CI/CD/CT (formation continue) automatisés, les délais de déploiement passent de quelques mois à quelques jours seulement. Ces pipelines peuvent automatiquement recycler les modèles lorsque les mesures de performances descendent en dessous des seuils définis ou lorsque de nouvelles données deviennent disponibles, éliminant ainsi le besoin d'une surveillance manuelle constante.
Les avantages financiers sont clairs. Entre 2022 et 2024, les coûts d’inférence de l’IA ont été divisés par 280, faisant de la surveillance continue et du recyclage une option pratique. Les pipelines automatisés permettent également de détecter les problèmes rapidement, évitant ainsi des erreurs coûteuses. Par exemple, une mauvaise qualité des données peut coûter aux entreprises 12,9 millions de dollars par an, tandis que les temps d'arrêt imprévus du système peuvent atteindre 125 000 dollars par heure. Les étapes automatisées de validation des données, telles que l'identification des incohérences de schéma, des valeurs nulles ou des changements de distribution, garantissent que les problèmes sont résolus dès la phase d'ingestion, évitant ainsi des problèmes plus importants à long terme.
L'automatisation accélère non seulement les flux de travail, mais réduit également les dépenses inutiles. Les pipelines auto-ajustables garantissent que le recyclage n'a lieu que lorsque cela est nécessaire, réduisant ainsi l'utilisation de ressources GPU coûteuses pendant les périodes d'inactivité. Des outils tels que LLM-as-a-Judge rationalisent les processus d'évaluation, réduisant les coûts tout en maintenant une cohérence de plus de 80 % sur des milliers de tests.
Les stratégies de test peuvent optimiser davantage les budgets. La simulation de tests avec des outils tels que Dev Proxy vous permet de tester les points de terminaison sans encourir de frais par appel. Commencer avec des modèles plus petits et des ensembles de données représentatifs permet de valider les idées avant de s'engager dans des évaluations à grande échelle. De plus, le marquage des ressources cloud par projet, équipe ou version de modèle fournit des informations détaillées sur la facturation, ce qui facilite la décision des flux de travail qui valent la peine d'être investis.
Les tests automatisés renforcent également la gouvernance en créant les pistes d’audit requises par les régulateurs. Les portes de gouvernance garantissent que les flux de travail s'arrêtent jusqu'à ce que les actifs critiques, tels que les schémas et les données de base, soient validés. Chaque instantané de modèle est soumis à une évaluation des risques standard, avec des résultats automatiquement enregistrés et des tickets déclenchés par une panne émis pour le suivi.
L’automatisation peut surveiller trois types clés de dérive : dérive des données (changements dans les distributions d'entrées), dérive des performances (diminution de la précision ou temps de réponse plus lents), et dérive de sécurité (toxicité accrue ou exposition d’informations sensibles). Les alertes signalent ces problèmes à un stade précoce, les empêchant d'affecter les utilisateurs finaux. De plus, les kill switch permettent aux équipes de désactiver rapidement les itinéraires ou les fonctionnalités de modèles problématiques lors d'incidents, démontrant ainsi une approche pratique de la gouvernance qui garantit que les systèmes restent sous contrôle lorsque cela est le plus important.
Les forfaits par répartition constituent un moyen intelligent de gérer les dépenses liées à l'IA tout en permettant aux équipes de se développer et de s'adapter sans effort. Ces plans s'appuient sur des stratégies telles que le suivi des coûts et l'évolutivité modulaire pour garantir que les ressources sont utilisées efficacement.
With pay-as-you-go pricing, you’re only charged for the tokens and compute time you actually use. Real-time dashboards provide insights into token consumption, latencies, and outcomes, helping to pinpoint inefficiencies and eliminate unnecessary spending. When combined with scale-to-zero capabilities, this model becomes even more effective - idle inference endpoints automatically shut down, so you’re not paying for unused GPU resources.
For tasks that aren’t time-sensitive, such as exploratory data analysis or offline model training, spot pricing offers a lower-cost alternative to on-demand rates. These savings add up, especially when paired with tools that track usage and performance in real time, allowing teams to fine-tune their compute needs and stay within budget.
Elastic compute ensures that your workflows can adapt to changing demands without manual adjustments. Features like autoscaling node pools and serverless architectures handle fluctuating workloads seamlessly, so there’s no need to overprovision resources for peak usage. By separating model artifacts from application code and using cloud storage, pods can start up almost instantly, making scaling operations faster and more efficient.
This approach is particularly valuable when transitioning from pilot projects to full-scale production. As the global MLOps market grows - expected to rise from $1.58 billion in 2024 to $2.33 billion by 2025 - organizations need scalable systems that won’t require constant rebuilding. Pay-as-you-go plans align costs with actual usage, making it easier to expand models, users, or teams without driving up expenses.
Les plans de paiement à l'utilisation fonctionnent main dans la main avec des outils d'équipe avancés pour rationaliser la gestion des coûts et les flux de travail opérationnels. Les outils modernes intègrent des fonctionnalités de gouvernance, de pistes d'audit et de sécurité telles que l'authentification unique (SSO) et le contrôle d'accès basé sur les rôles (RBAC) directement dans la couche d'orchestration. Ces capacités sont essentielles pour répondre aux exigences de conformité telles que SOC 2 ou ISO 27001.
Les plates-formes offrant la prise en charge des API compatibles OpenAI permettent aux équipes de basculer entre les fournisseurs ou les modèles LLM sans remanier leurs flux de travail, garantissant ainsi la flexibilité à mesure que de nouvelles technologies émergent. Les environnements gérés améliorent encore les opérations de l'équipe en intégrant des fonctionnalités telles que les autorisations, les SLA, le suivi centralisé des métadonnées et les contrôles d'autorisation. Ces systèmes s'adaptent non seulement à votre organisation, mais maintiennent également la transparence et le contrôle nécessaires pour répondre aux normes réglementaires, garantissant que chaque membre de l'équipe dispose du droit d'accès et que chaque action est enregistrée pour un audit.
La création de flux de travail d'IA efficaces nécessite des modèles puissants combinés à une approche structurée et évolutive. Les sept pratiques évoquées précédemment aident à transformer des initiatives d’IA disparates en processus rationalisés et prêts pour l’entreprise. En intégrant divers LLM, en maintenant une surveillance continue des coûts et en tirant parti des conceptions modulaires, vous pouvez éliminer les goulots d'étranglement et créer des flux de travail qui évoluent en fonction de vos besoins. Commencer par la gouvernance garantit que chaque décision d'IA est à la fois traçable et conforme, tandis que les invites communautaires et les cycles de tests automatisés accélèrent le développement sans compromettre la qualité. Ces stratégies constituent l’épine dorsale d’opérations d’IA efficaces et fiables.
Comme souligné précédemment, ces méthodes peuvent améliorer l'efficacité de 20 à 50 % sur les flux de travail tels que l'intégration et la gestion des incidents. Le suivi des coûts en temps réel, associé à des modèles de paiement à l'utilisation, permet d'aligner les dépenses sur l'utilisation, évitant ainsi les dépassements de budget tout en permettant une mise à l'échelle transparente. En intégrant l'automatisation et les boucles de rétroaction, les systèmes d'IA peuvent s'auto-optimiser, identifier les anomalies, suggérer des améliorations et gérer de manière autonome des tâches complexes.
L’évolution vers une gouvernance intégrée et des architectures adaptatives souligne l’importance de construire des flux de travail sur des bases solides. Des outils standardisés, des limites claires entre les composants et des traces détaillées garantissent que vos systèmes restent flexibles à mesure que de nouveaux modèles et fonctionnalités émergent. En vous concentrant sur des processus évolutifs et reproductibles, vous pouvez passer de projets pilotes à une production à grande échelle sans révisions constantes.
Ensemble, ces stratégies transforment des expériences fragmentées en flux de travail efficaces, responsables et soucieux des coûts. Prêt à prendre le contrôle de vos flux de travail d'IA ? Avec Prompts.ai, vous pouvez sécuriser vos modèles, gérer les coûts et évoluer sans effort. Accédez à plus de 35 modèles haut de gamme, utilisez les contrôles FinOps intégrés et mettez en œuvre une gouvernance de niveau entreprise, le tout au sein d'une seule interface. Prompts.ai élimine la prolifération des outils, garantit la conformité et permet à votre équipe de se concentrer sur l'innovation, transformant ainsi le chaos de l'IA en une opération rationalisée et axée sur le retour sur investissement.
Pour choisir le modèle de langage étendu (LLM) le plus adapté, commencez par identifier clairement vos besoins spécifiques, qu'il s'agisse d'écriture, de codage, de support client ou d'une autre application. Évaluez les modèles à l’aide d’une approche structurée qui prend en compte des facteurs tels que les performances, le coût et la confidentialité. Pour les tâches présentant un risque minimal, privilégiez les modèles plus rapides et plus économiques. D’un autre côté, les tâches à enjeux élevés exigent des modèles plus fiables et incluant une surveillance appropriée. L'analyse comparative est une étape critique pour garantir que le modèle choisi répond à la fois aux exigences de votre tâche et à vos objectifs opérationnels.
Pour garder les coûts de l'IA sous contrôle, il est essentiel de surveiller utilisation du jeton comme ça arrive. Cela implique le suivi des demandes, des invites et des appels modèles. En restant au courant de ces mesures, vous pouvez repérer les inefficacités et procéder à des ajustements pour optimiser l'utilisation des ressources, en maintenant un équilibre entre coût et performances.
Pour garder une longueur d'avance sur la dérive des modèles, mettez en place des systèmes de surveillance automatisés qui surveillent de près les mesures de performances et la qualité des données en temps réel. Ces outils peuvent détecter des changements tels que la dérive de concept, le changement de covariable ou la dérive d'étiquette en examinant les changements dans la distribution des données et la précision des prévisions. Lorsqu'une dérive est détectée, des déclencheurs de recyclage prédéfinis peuvent intervenir pour mettre à jour rapidement vos modèles, maintenant ainsi une validation cohérente et une intégration fluide dans vos processus MLOps.



















