Pago por Uso - AI Model Orchestration and Workflows Platform

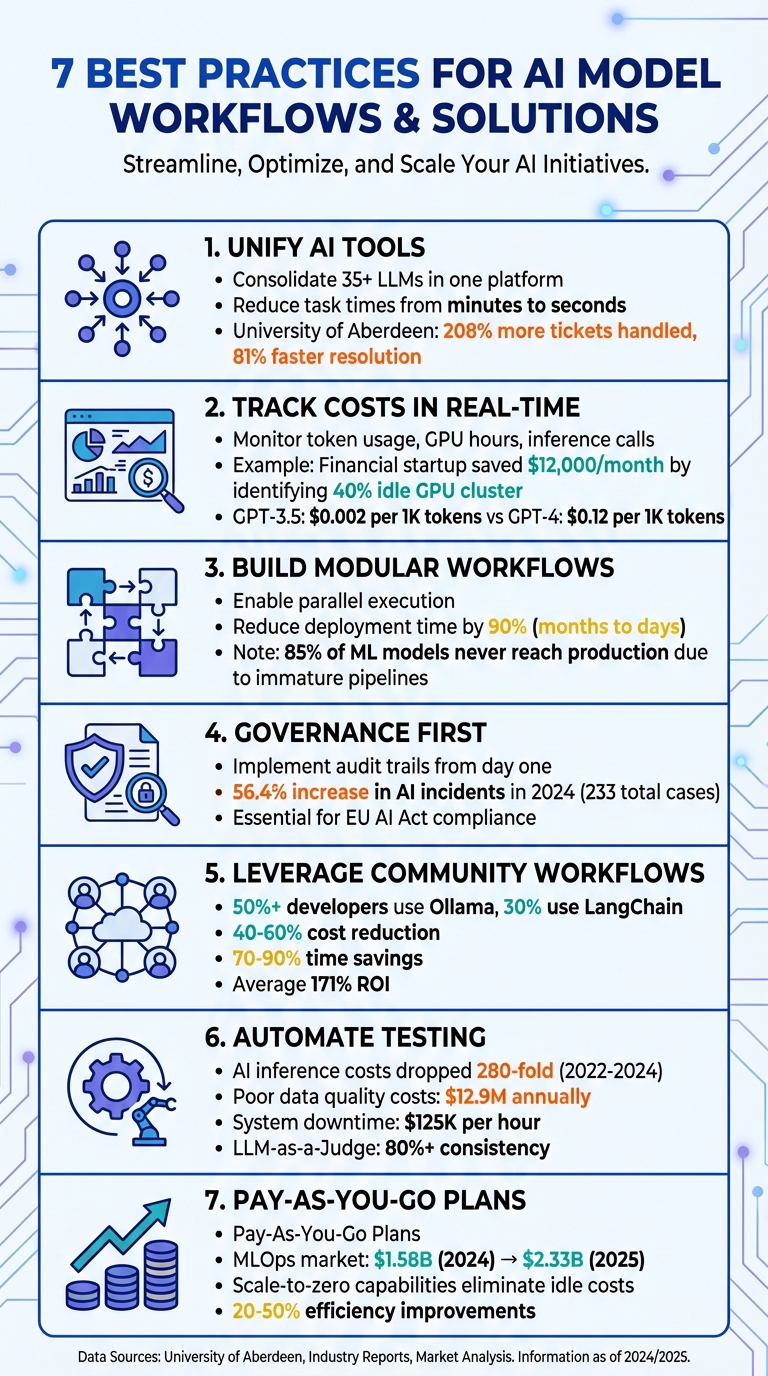
AI workflows in 2026 face challenges like fragmented tools, unchecked model drift, and escalating costs. To overcome these, organizations are adopting smarter, automated workflows that unify tools, improve governance, and optimize spending. Here’s how you can transform your AI operations:
Estas prácticas agilizan los flujos de trabajo, mejoran la supervisión y reducen los costos, lo que permite a las organizaciones escalar la IA de manera responsable y eficiente.
__XLATE_1__
La gestión de plataformas independientes para modelos como GPT-5, Claude, LLaMA y Gemini puede ralentizar las operaciones y crear obstáculos innecesarios. Al consolidar más de 35 LLM en una sola interfaz, Prompts.ai elimina la molestia de tener que hacer malabares con múltiples inicios de sesión y credenciales, lo que reduce los tiempos de las tareas de minutos a simples segundos.
Este tipo de integración genera ganancias de productividad mensurables. Por ejemplo, cuando la Universidad de Aberdeen adoptó un sistema basado en inteligencia artificial en septiembre de 2025, su equipo de TI logró manejar un 208 % más de tickets y redujo los tiempos de resolución en un 81 % [1]. Estos resultados resaltan cómo un sistema optimizado permite a los equipos centrarse en los resultados en lugar de perder tiempo gestionando herramientas fragmentadas. Este enfoque allana el camino para flujos de trabajo de IA más eficientes, confiables y rentables.
Una interfaz unificada no sólo ahorra tiempo, sino que garantiza una mayor confiabilidad y flexibilidad. Con todos los modelos accesibles desde una única plataforma, los equipos pueden cambiar sin problemas entre motores, manteniendo la continuidad incluso si un modelo falla o entrega resultados inexactos. Esta configuración proactiva evita procesos descontrolados, que pueden provocar un aumento vertiginoso de los costos de la nube cuando los agentes automatizados funcionan sin los controles adecuados.
La plataforma también permite realizar pruebas de rendimiento en paralelo, para que pueda evaluar qué modelo se adapta mejor a tareas específicas. Por ejemplo, las consultas de atención al cliente pueden dirigirse a un LLM, los proyectos creativos a otro y el procesamiento de datos a un tercero, todo ello gestionado desde el mismo panel. Este diseño independiente del modelo garantiza que no esté atado a las limitaciones o precios de un solo proveedor, lo que le brinda la libertad de optimizar el rendimiento y los costos.
Prompts.ai lleva la gestión de costos al siguiente nivel al ofrecer información en tiempo real sobre el uso de tokens en todos los modelos. Esta transparencia ayuda a prevenir los excesos presupuestarios antes de que ocurran. Una capa FinOps integrada realiza un seguimiento del gasto en el nivel inicial, lo que facilita la identificación de qué flujos de trabajo ofrecen valor y cuáles agotan los recursos. Las organizaciones que utilizan la automatización del flujo de trabajo mediante IA han obtenido un retorno de la inversión del 84 % cuando pueden vincular los gastos con los resultados empresariales. Databricks, por ejemplo, redujo los tickets de soporte en un 23 % mediante una clasificación inteligente impulsada por modelos de datos limpios y un seguimiento de costos transparente [1].
Los créditos TOKN de pago por uso de la plataforma alinean los gastos con el uso real, eliminando la necesidad de pagar por la capacidad no utilizada. Al consolidar los costos en múltiples modelos, los equipos pueden ahorrar hasta un 98 % en comparación con mantener suscripciones separadas para cada herramienta, lo que genera ahorros significativos en todos los proyectos y departamentos.
Prompts.ai también fortalece la gobernanza y el cumplimiento, ofreciendo pistas de auditoría unificadas que respaldan tanto los requisitos regulatorios como las mejoras del flujo de trabajo. La plataforma clasifica las tareas en niveles de riesgo, asegurando que las operaciones de alto riesgo (como las tareas de Nivel 4 con potencial catastrófico) permanezcan bajo supervisión humana hasta que los sistemas de IA sean completamente confiables.
Con cifrado de extremo a extremo y estrictos controles de acceso, los datos confidenciales permanecen protegidos contra configuraciones incorrectas o infracciones. Dado que el 78 % de las organizaciones utilizan actualmente la IA en al menos un área de su negocio [2], Prompts.ai proporciona seguridad de nivel empresarial al tiempo que mantiene la velocidad y la agilidad que los equipos necesitan para innovar. Cada interacción es segura, rastreable y auditable, lo que brinda a las organizaciones la confianza para escalar la IA de manera responsable.
Las cargas de trabajo de IA a menudo generan gastos impredecibles que no pueden comprenderse completamente a través de facturas mensuales. FinOps en tiempo real cambia esto al ofrecer información inmediata sobre los costos a medida que ocurren. Al rastrear el uso de tokens, las horas de GPU y las llamadas de inferencia casi en tiempo real, los equipos pueden identificar y abordar los excesos presupuestarios antes de que se salgan de control.
Por ejemplo, una startup de análisis financiero descubrió que el 40% de su clúster de 8 GPU estaba inactivo, desperdiciando casi 12.000 dólares cada mes. A través del monitoreo en tiempo real, el equipo identificó esta ineficiencia a mitad del sprint e hizo ajustes para optimizar la capacidad de inmediato.
El seguimiento granular por equipo, proyecto o cliente perfecciona aún más los modelos de contracargo. Al adjuntar metadatos, como los ID de los clientes, a las solicitudes de API, el gasto se vuelve más transparente. Esto permite a los departamentos pagar sólo por lo que utilizan, allanando el camino para operaciones que son escalables y rentables.
Real-time tracking doesn’t just monitor costs - it actively supports smarter scaling decisions. Autoscaling can now factor in both performance metrics (like latency) and financial data (such as cost per prediction). For example, during traffic spikes, systems can throttle or reroute requests based on cost signals, ensuring resources are used efficiently.
__XLATE_13__
StreamForge AI adoptó esta estrategia en septiembre de 2025 al integrar Kubecost con Prometheus y mostrar datos de utilización en paneles de Grafana actualizados cada cinco minutos. Utilizando un enfoque de escalado automático de señalización dual (equilibrando la latencia p95 y las métricas de costo por solicitud), aumentaron significativamente la utilización de la GPU y mejoraron la rentabilidad de más de 300 trabajos de capacitación diarios. Este enfoque en tiempo real ayuda a evitar costosas configuraciones erróneas que podrían agotar los presupuestos mensuales.
Centralizing cost tracking across multiple AI providers is essential when managing diverse models. A unified AI gateway simplifies this process by consolidating token usage, latency, and cost data into a single, reliable source. Whether you’re using OpenAI, Anthropic, or self-hosted models, this centralized system eliminates the need to piece together fragmented billing data.
Este nivel de integración es crucial porque los diferentes modelos tienen precios muy diferentes. Por ejemplo, GPT-3.5-Turbo cuesta alrededor de $0,002 por cada 1000 tokens, mientras que GPT-4 puede subir hasta $0,12 por cada 1000 tokens dependiendo de la ventana de contexto. El seguimiento en tiempo real permite a los equipos comparar estos costos y enrutar las tareas al modelo más económico. Ya sea que se traten consultas simples de clientes o análisis complejos, las tareas se asignan al modelo correcto en función de los datos de costos en vivo, lo que garantiza que los flujos de trabajo sigan siendo eficientes y económicos.
Dividir los flujos de trabajo de IA en componentes modulares revoluciona la forma en que se implementan y escalan. En lugar de depender de una tubería única y rígida para manejar cada etapa, un enfoque modular permite actualizar o reemplazar piezas individuales sin interrumpir todo el sistema.
Este diseño también permite la ejecución paralela, donde se pueden ejecutar múltiples tareas al mismo tiempo. Por ejemplo, un servicio de traducción multilingüe puede procesar varias versiones de idiomas simultáneamente en lugar de una tras otra, lo que reduce significativamente el tiempo de procesamiento. La adopción de prácticas MLOps acelera aún más la implementación, reduciendo el tiempo para pasar un modelo a producción hasta en un 90%. Los canales automatizados pueden reducir los plazos de implementación de meses a solo días.
Otra ventaja es la rejugabilidad. Si un paso específico, como el posprocesamiento, encuentra un problema, puede volver a ejecutar solo ese módulo usando artefactos almacenados en lugar de rehacer todo el flujo de trabajo. Este enfoque de repetición dirigida ahorra tiempo y recursos, especialmente para tareas que requieren una potencia computacional significativa. Los flujos de trabajo modulares también facilitan la estandarización e integración segura de componentes en todo el sistema.
Una vez que se ha establecido una base modular, resulta esencial garantizar una comunicación fluida entre los componentes. La estandarización de los formatos de entrada y salida ayuda a evitar errores en cascada. Por ejemplo, si un módulo de ingesta de datos genera un archivo JSON claramente definido que se alinea perfectamente con la entrada esperada de un módulo de inferencia, se eliminan posibles errores de comunicación.
Separar la lógica de la IA de la lógica de las políticas mejora aún más la mantenibilidad. Esto le permite administrar el comportamiento del modelo dinámico independientemente de las reglas comerciales fijas, como se destaca en la Guía prescriptiva de AWS. Herramientas como Docker o Kubernetes pueden contener módulos, garantizando que sigan siendo portátiles en diferentes entornos. Un módulo en contenedores puede operar de manera consistente en desarrollo, puesta en escena y producción, e incluso puede realizar la transición entre proveedores de nube sin requerir cambios. Para la orquestación, AWS Step Functions proporciona coordinación sin servidor con reintentos integrados, mientras que Apache Airflow ofrece flexibilidad basada en Python para administrar flujos de trabajo más complejos.
Los diseños modulares también aportan beneficios financieros al permitirle asignar los recursos adecuados para cada tarea. Los modelos de razonamiento complejos, que consumen muchos recursos, pueden reservarse para análisis exigentes, mientras que las tareas más simples se manejan mediante modelos menos costosos. Esto garantiza que los recursos computacionales se utilicen de forma inteligente.
El seguimiento de metadatos a nivel de módulo mejora la transparencia. Al adjuntar detalles como marcas de tiempo, versiones de modelos y datos de costos a cada artefacto a medida que avanza por el proceso, los equipos obtienen un seguimiento de auditoría claro. Esto no sólo ayuda en la depuración sino también en el seguimiento financiero. Alinear los costos con métricas específicas del módulo permite realizar un presupuesto preciso manteniendo la flexibilidad. Además, establecer límites en el tamaño de los lotes y la simultaneidad puede ayudar a evitar gastos inesperados durante períodos de alta demanda.
It’s worth noting that about 85% of machine-learning models never make it to production, often due to immature pipeline structures. Modular, iterative workflows offer a way to overcome this challenge. Teams can start small, validate one module at a time, and gradually scale up, reducing risks and ensuring systems are ready for production.
Incorporar la gobernanza en su flujo de trabajo de IA desde el principio le evita ajustes costosos en el futuro. Al aprovechar las evaluaciones automatizadas y la transparencia mencionadas anteriormente, puede garantizar que el cumplimiento esté integrado en sus procesos desde el principio. Tan pronto como se crea un modelo o caso de uso, generar un ticket de seguimiento en su herramienta de flujo de trabajo y asignar un nivel de riesgo inicial. Las aplicaciones de alto riesgo, como la calificación crediticia o los sistemas de contratación, exigen procesos de aprobación más estrictos y un seguimiento más estrecho en comparación con las herramientas de menor riesgo utilizadas internamente. Este "giro a la izquierda" Este enfoque lo mantiene preparado para los requisitos regulatorios, especialmente con marcos como la Ley de IA de la UE que exige documentación detallada de los procesos de capacitación y evaluación.
Una piedra angular del cumplimiento es seguimiento de linaje, que proporciona una ruta clara y reproducible desde los datos sin procesar hasta el resultado final del modelo. Combine el seguimiento del linaje con trazabilidad de instantáneas, lo que garantiza que el estado exacto de su código, datos y configuraciones se conserve antes de la implementación. Esto le permite reproducir cualquier versión del modelo según sea necesario. La investigación de la industria destaca la urgencia de estas medidas, señalando un aumento del 56,4 % en los incidentes relacionados con la IA en 2024, con un total de 233 casos, lo que enfatiza la necesidad de pistas de auditoría sólidas.
Los seguimientos de auditoría agilizan la resolución de problemas al vincular directamente los errores con sus orígenes. En lugar de examinar los registros manualmente, los ingenieros pueden utilizar el seguimiento del linaje para identificar rápidamente dónde se rompió una tubería o dónde disminuyó la calidad de los datos. La automatización de las tareas de gobernanza, como comprobaciones de activos y evaluaciones de riesgos, no solo garantiza el cumplimiento, sino que también mantiene sus iniciativas de IA avanzando de manera eficiente a medida que crecen. Al automatizar estos pasos, puede reducir los tiempos de aprobación y mantener la coherencia en todas las operaciones.
Una gobernanza de datos sólida es esencial para mantener datos de alta calidad. La gestión centralizada de metadatos consolida la información sobre todos los activos de IA en un solo lugar, eliminando redundancias y garantizando operaciones fluidas. Cuando se realiza un seguimiento de cada componente, desde las indicaciones hasta las versiones del modelo, con marcas de tiempo y detalles de costos, los equipos obtienen una historial completo de ejecución. Esto hace que las tuberías sean más fáciles de reproducir y refinar. Los registros de auditoría automatizados reducen aún más los errores humanos, estableciendo un flujo de trabajo confiable y repetible.
Estas estrategias de gobernanza se integran perfectamente con flujos de trabajo modulares, lo que garantiza que el cumplimiento siga siendo una parte central de su sistema a medida que escala.
Una capa de gobernanza unificada une flujos de trabajo optimizados y transparencia de costos, garantizando el cumplimiento en todos los ámbitos. Muchos sistemas, como Snowflake, Databricks, plataformas en la nube y entornos de borde, operan en múltiples plataformas. Sin un enfoque de gobernanza unificado, se corre el riesgo de una "IA en la sombra", donde los modelos se implementan sin supervisión, lo que hace imposible la verificación del cumplimiento. Trazabilidad entre sistemas garantiza que el linaje de datos en tiempo de ejecución se capture en consultas, cuadernos, trabajos y paneles, manteniendo el cumplimiento a medida que los datos se mueven entre plataformas. Las interfaces estandarizadas, como el Protocolo de contexto modelo (MCP) con puertas de enlace centralizadas, permiten un registro coherente y un seguimiento de solicitudes entre servidores e inquilinos. Esto le brinda un seguimiento de auditoría completo, sin importar dónde se realice el trabajo.
Crear flujos de trabajo desde cero puede llevar mucho tiempo y ser ineficiente. Marcos impulsados por la comunidad como LangChain y Ollama se han convertido en soluciones de referencia, que ofrecen plantillas prediseñadas para encadenar mensajes e integrar herramientas. Estos marcos se adoptan ampliamente: más del 50 % de los desarrolladores utilizan Ollama y casi un tercio confía en LangChain para gestionar agentes de IA. Reemplazan el frágil código personalizado con funciones flexibles y sin servidor que funcionan de forma independiente, lo que las hace más fáciles de administrar y escalar.
El beneficio clave es escalabilidad sin complejidad. Al confiar en patrones probados por la comunidad, puede cambiar de modelo, como pasar de GPT a Amazon Bedrock, sin necesidad de revisar su lógica de orquestación. Esta flexibilidad acelera la implementación manteniendo la coherencia. Las investigaciones muestran que, si bien la orquestación es una prioridad para muchas organizaciones, sólo unas pocas la han implementado por completo. Los flujos de trabajo comunitarios ofrecen una solución práctica que permite una integración perfecta entre varias plataformas de IA.
Los flujos de trabajo comunitarios también abordan el desafío de integrar herramientas de inteligencia artificial entre plataformas. Estándares como el Protocolo de contexto modelo (MCP) abordar el problema de la expansión de plataformas, una preocupación para 63% de los ejecutivos. Estos protocolos permiten que los agentes y herramientas de IA trabajen juntos en plataformas como Gmail, Slack y CRM sin necesidad de ingresar datos manualmente. Por ejemplo, una solicitud sencilla en lenguaje natural, como "resumir los últimos 10 correos electrónicos de Gmail" - puede desencadenar tareas estructuradas con conexiones API preconfiguradas.
__XLATE_52__
La interoperabilidad es fundamental, con 87% de los líderes de TI identificándolo como esencial para la adopción de sistemas impulsados por IA. Los flujos de trabajo comunitarios están diseñados teniendo en cuenta la resiliencia y ofrecen características como reintentos automatizados, tiempos de espera y ejecución paralela para manejar posibles fallas del modelo. Estas salvaguardias son vitales, especialmente porque El 87% de los desarrolladores se preocupan por la precisión de la IA, y El 81% está preocupado por la seguridad y la privacidad.. Más allá de mejorar la integración, estos flujos de trabajo también ayudan a reducir los costos significativamente.
El uso de plantillas comunitarias para transformar indicaciones en lenguaje natural en flujos de trabajo automatizados puede reducir drásticamente los costos y ahorrar tiempo. Informe de organizaciones Reducciones de costos del 40-60% y 70-90% de ahorro de tiempo cuando adoptan la automatización de la IA a través de estos flujos de trabajo. Comenzar con soluciones probadas elimina la necesidad de costosos procesos de prueba y error.
Estos flujos de trabajo también mejoran la transparencia al incorporar pistas de auditoría estandarizadas y seguimiento de metadatos. Registran automáticamente detalles como fuentes de datos, permisos e historiales de decisiones de los agentes. Muchos incluyen humano en el circuito puntos de control para la revisión manual de tareas sensibles o de alto costo, asegurando la supervisión donde más importa. Al gestionar los costos de inferencia durante el escalamiento, las empresas han visto un promedio 171% de retorno de la inversión al aprovechar los flujos de trabajo creados por la comunidad.
La automatización de las pruebas y evaluaciones es la pieza final para crear un ciclo de vida de IA fluido. Elimina los retrasos causados por las pruebas manuales, que a menudo impiden que los modelos lleguen a producción: el 85% de los modelos no se implementan debido a ineficiencias en el proceso. Al aprovechar los canales automatizados de CI/CD/CT (capacitación continua), los tiempos de implementación se reducen de meses a solo días. Estos canales pueden volver a entrenar modelos automáticamente cuando las métricas de rendimiento caen por debajo de los umbrales establecidos o cuando hay nuevos datos disponibles, eliminando la necesidad de una supervisión manual constante.
Los beneficios financieros son claros. Entre 2022 y 2024, los costos de inferencia de IA se redujeron 280 veces, lo que hace que el monitoreo y el reentrenamiento continuo sean una opción práctica. Los procesos automatizados también ayudan a detectar problemas de manera temprana, evitando errores costosos. Por ejemplo, la mala calidad de los datos puede costar a las empresas 12,9 millones de dólares al año, mientras que el tiempo de inactividad no planificado del sistema puede alcanzar los 125.000 dólares por hora. Los pasos de validación de datos automatizados, como la identificación de discrepancias en los esquemas, valores nulos o cambios de distribución, garantizan que los problemas se aborden en la etapa de ingesta, evitando problemas mayores en el futuro.
La automatización no sólo acelera los flujos de trabajo sino que también reduce gastos innecesarios. Los canales autoajustables garantizan que el reentrenamiento se realice solo cuando sea necesario, lo que reduce el uso de costosos recursos de GPU durante los períodos de inactividad. Herramientas como LLM-as-a-Judge agilizan los procesos de evaluación, reducen costos y mantienen una coherencia de más del 80 % en miles de pruebas.
Las estrategias de prueba pueden optimizar aún más los presupuestos. La simulación de pruebas con herramientas como Dev Proxy le permite realizar pruebas de estrés en los puntos finales sin incurrir en tarifas por llamada. Comenzar con modelos más pequeños y conjuntos de datos representativos ayuda a validar ideas antes de comprometerse con evaluaciones a gran escala. Además, etiquetar los recursos de la nube por proyecto, equipo o versión del modelo proporciona información detallada sobre facturación, lo que facilita decidir qué flujos de trabajo valen la inversión.
Las pruebas automatizadas también refuerzan la gobernanza al crear las pistas de auditoría que requieren los reguladores. Las puertas de gobernanza garantizan que los flujos de trabajo se detengan hasta que se validen los activos críticos, como esquemas y datos de referencia. Cada instantánea del modelo se somete a una evaluación de riesgos estándar, con resultados registrados automáticamente y tickets activados por fallas emitidos para seguimiento.
La automatización puede monitorear tres tipos clave de deriva: deriva de datos (cambios en las distribuciones de insumos), deriva de rendimiento (disminución de la precisión o tiempos de respuesta más lentos), y deriva de seguridad (aumento de la toxicidad o exposición de información sensible). Las alertas señalan estos problemas con antelación, evitando que afecten a los usuarios finales. Además, los interruptores de apagado permiten a los equipos desactivar rápidamente rutas o características problemáticas del modelo durante incidentes, lo que demuestra un enfoque práctico de gobernanza que garantiza que los sistemas permanezcan bajo control cuando más importa.
Los planes de pago por uso son una forma inteligente de gestionar los gastos de IA y, al mismo tiempo, permiten que los equipos crezcan y se adapten sin esfuerzo. Estos planes se basan en estrategias como el seguimiento de costos y la escalabilidad modular para garantizar que los recursos se utilicen de manera eficiente.
With pay-as-you-go pricing, you’re only charged for the tokens and compute time you actually use. Real-time dashboards provide insights into token consumption, latencies, and outcomes, helping to pinpoint inefficiencies and eliminate unnecessary spending. When combined with scale-to-zero capabilities, this model becomes even more effective - idle inference endpoints automatically shut down, so you’re not paying for unused GPU resources.
For tasks that aren’t time-sensitive, such as exploratory data analysis or offline model training, spot pricing offers a lower-cost alternative to on-demand rates. These savings add up, especially when paired with tools that track usage and performance in real time, allowing teams to fine-tune their compute needs and stay within budget.
Elastic compute ensures that your workflows can adapt to changing demands without manual adjustments. Features like autoscaling node pools and serverless architectures handle fluctuating workloads seamlessly, so there’s no need to overprovision resources for peak usage. By separating model artifacts from application code and using cloud storage, pods can start up almost instantly, making scaling operations faster and more efficient.
This approach is particularly valuable when transitioning from pilot projects to full-scale production. As the global MLOps market grows - expected to rise from $1.58 billion in 2024 to $2.33 billion by 2025 - organizations need scalable systems that won’t require constant rebuilding. Pay-as-you-go plans align costs with actual usage, making it easier to expand models, users, or teams without driving up expenses.
Los planes de pago por uso funcionan de la mano con herramientas avanzadas del equipo para optimizar la gestión de costos y los flujos de trabajo operativos. Las herramientas modernas integran gobernanza, seguimientos de auditoría y características de seguridad como el inicio de sesión único (SSO) y el control de acceso basado en roles (RBAC) directamente en la capa de orquestación. Estas capacidades son esenciales para cumplir con requisitos de cumplimiento como SOC 2 o ISO 27001.
Las plataformas que ofrecen soporte para API compatibles con OpenAI permiten a los equipos cambiar entre proveedores o modelos de LLM sin revisar sus flujos de trabajo, lo que garantiza flexibilidad a medida que surgen nuevas tecnologías. Los entornos administrados mejoran aún más las operaciones del equipo al incorporar características como permisos, SLA, seguimiento centralizado de metadatos y controles de autorización. Estos sistemas no solo se adaptan a su organización, sino que también mantienen la transparencia y el control necesarios para cumplir con los estándares regulatorios, garantizando que cada miembro del equipo tenga el acceso correcto y que cada acción se registre para su auditoría.
Para crear flujos de trabajo de IA eficaces se necesitan modelos potentes combinados con un enfoque estructurado y escalable. Las siete prácticas analizadas anteriormente ayudan a transformar iniciativas de IA inconexas en procesos optimizados y listos para la empresa. Al incorporar diversos LLM, mantener un monitoreo continuo de costos y aprovechar los diseños modulares, puede eliminar cuellos de botella y crear flujos de trabajo que evolucionen junto con sus necesidades. Comenzar con la gobernanza garantiza que cada decisión de la IA sea rastreable y conforme, mientras que las indicaciones impulsadas por la comunidad y los ciclos de prueba automatizados aceleran el desarrollo sin comprometer la calidad. Estas estrategias forman la columna vertebral de operaciones de IA eficientes y confiables.
Como se destacó anteriormente, estos métodos pueden mejorar la eficiencia entre un 20 % y un 50 % en flujos de trabajo como la incorporación y la gestión de incidentes. El seguimiento de costos en tiempo real, junto con modelos de pago por uso, mantiene los gastos alineados con el uso, evitando excesos presupuestarios y al mismo tiempo permite un escalamiento fluido. Al integrar bucles de automatización y retroalimentación, los sistemas de IA pueden autooptimizarse, identificar anomalías, sugerir mejoras y gestionar tareas complejas de forma autónoma.
El avance hacia una gobernanza integrada y arquitecturas adaptables subraya la importancia de construir flujos de trabajo sobre bases sólidas. Las herramientas estandarizadas, los límites claros de los componentes y los seguimientos detallados garantizan que sus sistemas se mantengan flexibles a medida que surgen nuevos modelos y capacidades. Al centrarse en procesos escalables y repetibles, puede pasar de proyectos piloto a producción a gran escala sin revisiones constantes.
Juntas, estas estrategias convierten experimentos fragmentados en flujos de trabajo eficientes, responsables y conscientes de los costos. ¿Listo para tomar el control de sus flujos de trabajo de IA? Con Prompts.ai, puede proteger sus modelos, administrar costos y escalar sin esfuerzo. Acceda a más de 35 modelos principales, utilice controles FinOps integrados e implemente gobernanza de nivel empresarial, todo dentro de una única interfaz. Prompts.ai elimina la dispersión de herramientas, garantiza el cumplimiento y permite que su equipo se centre en la innovación, convirtiendo el caos de la IA en una operación optimizada impulsada por el retorno de la inversión.
Para elegir el modelo de lenguaje grande (LLM) más adecuado, comience por identificar claramente sus necesidades específicas, ya sea de escritura, codificación, atención al cliente u otra aplicación. Evalúe modelos utilizando un enfoque estructurado que considere factores como el rendimiento, el costo y la privacidad. Para tareas con riesgo mínimo, priorice modelos que sean más rápidos y económicos. Por otro lado, las tareas de alto riesgo exigen modelos que sean más confiables e incluyan una supervisión adecuada. La evaluación comparativa es un paso fundamental para garantizar que el modelo elegido cumpla tanto con los requisitos de su tarea como con sus objetivos operativos.
Para mantener los costos de la IA bajo control, es esencial monitorear uso de tokens como sucede. Esto implica el seguimiento de solicitudes, indicaciones y llamadas de modelos. Al estar al tanto de estas métricas, puede detectar ineficiencias y realizar ajustes para optimizar el uso de recursos, manteniendo un equilibrio entre costo y rendimiento.
Para adelantarse a la deriva del modelo, configure sistemas de monitoreo automatizados que vigilen de cerca las métricas de rendimiento y la calidad de los datos en tiempo real. Estas herramientas pueden detectar cambios como la deriva de conceptos, cambios de covariables o deriva de etiquetas al examinar los cambios en la distribución de datos y la precisión de las predicciones. Cuando se detecta una desviación, se pueden activar activadores de reentrenamiento predefinidos para actualizar sus modelos rápidamente, manteniendo una validación consistente y una integración fluida dentro de sus procesos MLOps.



















