Nutzungsbasierte Abrechnung - AI Model Orchestration and Workflows Platform

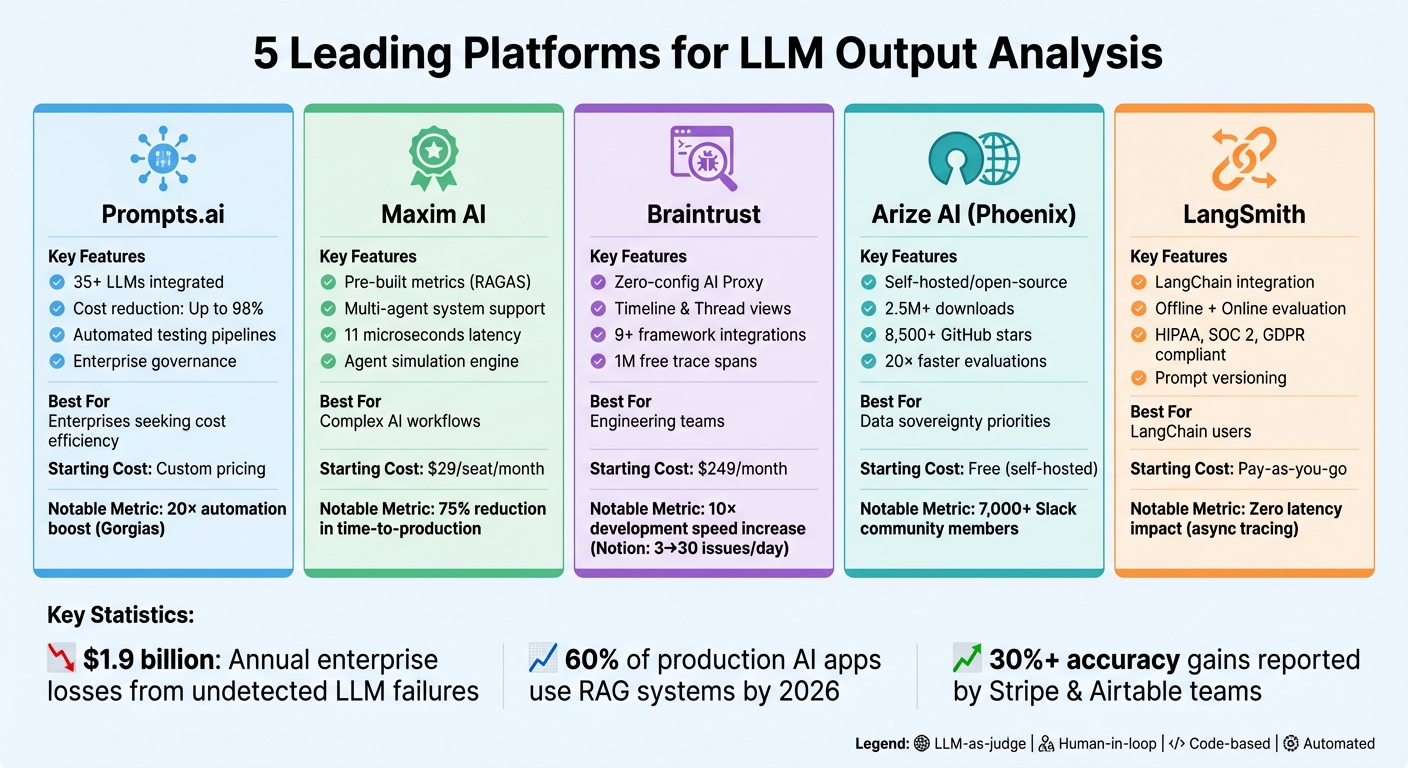
Große Sprachmodelle (LLMs) sind leistungsstark, aber unvorhersehbar und führen häufig zu inkonsistenten oder kostspieligen Ergebnissen. Um diese Herausforderungen zu bewältigen, verlassen sich Unternehmen auf spezielle Tools zur Bewertung, Überwachung und zum Kostenmanagement. Dieser Artikel stellt vor fünf Plattformen die die LLM-Ausgabeanalyse optimieren:
Jede Plattform befasst sich mit einzigartigen Aspekten der LLM-Workflows, von der Verbesserung der Genauigkeit über die Kostensenkung bis hin zur Sicherstellung der Compliance.
| Plattform | Hauptmerkmale | Am besten für | Startkosten |
|---|---|---|---|
| Prompts.ai | Zentraler LLM-Zugriff, kostensparende FinOps-Tools | Unternehmen auf der Suche nach Kosteneffizienz | Individuelle Preise |
| Maxim AI | Vorgefertigte Metriken, Unterstützung für Multiagentensysteme | Teams verwalten komplexe KI-Workflows | 29 $/Sitzplatz/Monat |
| Braintrust | Debugging-Tools, Multi-Turn-Konversationstests | Ingenieurteams | 249 $/Monat |
| Arize KI | Open-Source, detaillierte Rückverfolgung, Halluzinationsprüfungen | Organisationen legen Wert auf Datenkontrolle | Kostenlos (selbst gehostet) |
| LangSmith | LangChain-Integration, sofortige Versionierung | LangChain-Benutzer | Pay-as-you-go |
Diese Plattformen vereinfachen das LLM-Management und sorgen für skalierbare, zuverlässige und kostengünstige KI-Operationen.
__XLATE_5__
Prompts.ai brings together 35+ top-tier LLMs - including GPT‑5, Claude, LLaMA, and Gemini - into one unified platform designed for enterprise-level prompt engineering and detailed output analysis. It simplifies evaluation with automated testing pipelines.
Prompts.ai verfügt über Evaluierungspipelines, mit denen über 20 Tests für Prompt-Datensätze ausgeführt werden können. Dazu gehören Methoden wie LLM-Assertionen (unter Verwendung von KI zur Bewertung von Ausgaben), semantische Ähnlichkeitsprüfungen durch Kosinusähnlichkeit, exakte Übereinstimmungsbewertungen und Regex-basierter Mustervergleich. Teams können über ein benutzerfreundliches Dashboard auch Human-in-the-Loop-Bewertungen integrieren, sodass Fachexperten die Ergebnisse manuell bewerten können, als Teil des verstärkenden Lernens aus menschlichem Feedback.
For instance, Gorgias, a customer support platform, used Prompts.ai to scale its AI-powered helpdesk to support millions of shoppers. This led to a 20× boost in automation. Their ML engineers and support teams run daily regression tests on backtest datasets to catch potential issues before deployment.
Diese strengen Testfunktionen gewährleisten eine reibungslose Integration in aktuelle Arbeitsabläufe.
Prompts.ai’s evaluation pipelines seamlessly integrate with CI/CD workflows and enable backtesting against historical production data. The platform supports connections through external HTTP endpoints, custom Python/JavaScript scripts, and Model Context Protocol (MCP) actions.
Speak, eine Sprachlern-App, nutzte diese Automatisierungsfunktionen, um Monate der Lehrplanentwicklung auf nur eine Woche zu verkürzen. Diese Effizienz ermöglichte es ihnen, KI-gesteuerte Funktionen gleichzeitig in zehn neuen Märkten einzuführen.
Prompts.ai hilft Teams auch dabei, Kosten zu optimieren, indem es parallele Modellvergleichsansichten bietet. Diese Vergleiche ermöglichen es Benutzern, Kompromisse zwischen API-Kosten, Latenz und Qualitätswerten abzuwägen. Teams können Ausgaben zusammenfassen oder kleinere, schnellere Modelle für Zwischenaufgaben verwenden, um die Token-Nutzung zu reduzieren. NoRedInk, das 60 % der Schulbezirke in den USA bedient, nutzt diese kostensparenden Funktionen, um KI-generiertes Feedback zu über 1 Million Schülernoten bereitzustellen und dabei die Qualität auf Lehrerniveau aufrechtzuerhalten.
Prompts.ai verbessert die Zusammenarbeit, indem es alle Beteiligten mit Tools zur Verfeinerung der LLM-Ergebnisse ausstattet. Ein visueller Editor ohne Code ermöglicht es technisch nicht versierten Benutzern, Eingabeaufforderungen zu bearbeiten und zu testen, ohne auf Ingenieure angewiesen zu sein. Die zentralisierte Prompt Registry sorgt für eine effiziente Versionsverwaltung.
ParentLab beispielsweise hat in nur sechs Monaten über 400 Entwicklungsstunden eingespart, indem es nicht-technischen Fachexperten ermöglicht hat, 700 zeitnahe Überarbeitungen zu verwalten.
__XLATE_12____XLATE_13__
Die Plattform sammelt außerdem Benutzerbewertungen und übersetzt sie in Leistungsbewertungen, wodurch eine kontinuierliche Feedbackschleife entsteht, um die Ausgabequalität aller integrierten Modelle zu verbessern.
Maxim AI bietet umfassende Test- und Überwachungstools, die maschinengesteuerte Auswertungen mit menschlichem Feedback kombinieren, um Teams bei der Verwaltung komplexer KI-Workflows zu unterstützen. Seine Funktionen sind darauf ausgelegt, gründliche Bewertungen zu gewährleisten, die für die Aufrechterhaltung einer starken LLM-Leistung von entscheidender Bedeutung sind.
Maxim AI verwendet ein robustes Bewertungsframework, das deterministische Tests, statistische Methoden und automatisierte Beurteilungstools umfasst. Der Evaluator Store bietet vorgefertigte Metriken wie RAGAS an, die auf abrufgestützte Erzeugungssysteme zugeschnitten sind – Schlüsselkomponenten in etwa 60 % der Produktions-KI-Anwendungen bis 2026. Darüber hinaus Metriken auf Knotenebene help identify failures in retrieval and generation processes. The platform’s Agentensimulation Die Engine ermöglicht Multi-Turn-Konversationstests und die Erstellung von Benutzerpersönlichkeiten für Bewertungen vor der Bereitstellung. Unternehmen wie Clinc und Mindtickle haben durch die Einführung dieser Qualitätsstandards eine Verkürzung der Produktionszeit um 75 % gemeldet.
Maxim AI’s evaluation tools integrate effortlessly with today’s development environments. It supports SDKs in Python, TypeScript, Java, and Go, while offering compatibility with platforms like LangChain, LangGraph, Crew AI, OpenAI, Anthropic, Mistral, and AWS Bedrock. The platform also adheres to OpenTelemetry Standards für verteiltes Tracing und verbindet sich mit Tools wie Slack und PagerDuty für Echtzeitwarnungen. Unternehmensbenutzer profitieren von Bereitstellungsoptionen, die Cloud- und In-VPC-Hosting umfassen und alle die SOC2-, HIPAA- und DSGVO-Konformitätsanforderungen erfüllen.
Der Bifrost LLM-Gateway nutzt semantisches Caching, um Kosten zu senken, und überwacht gleichzeitig die Token-Nutzung und API-Kosten, um teure Arbeitsabläufe zu identifizieren und zu bewältigen. Dies gewährleistet einen effizienten Betrieb bei Produktionsskalen.
Maxim AI’s No-Code-Benutzeroberfläche ermöglicht Produktmanagern und Designern, mit Eingabeaufforderungen zu experimentieren und unabhängig Bewertungen durchzuführen. Kellie Maloney, Produktleiterin bei Rise Science, teilte mit:
__XLATE_29__
Die Plattform umfasst außerdem Anmerkungswarteschlangen für Human-in-the-Loop-Überprüfungen, ein zentrales Prompt-CMS mit Versionskontrolle und RBAC mit SAML/SSO-Unterstützung. Teams, die diese Kollaborationstools nutzen, konnten die Versandgeschwindigkeit verfünffachen, die Iteration rationalisieren und die Produktionseinführung beschleunigen.
Braintrust kombiniert Offline-Experimente mit Online-Bewertungen, um Teams einen vollständigen Überblick über die LLM-Leistung von der Entwicklung bis zur Bereitstellung zu geben.
Braintrust bietet mehrere Möglichkeiten zur Bewertung der Ausgabequalität auf einer Skala von 0 bis 1. Teams können automatisierte Bewerter für Aufgaben wie die Prüfung von Sachverhalt und Ähnlichkeit verwenden, sich auf LLM-as-a-Judge-Bewertungen verlassen oder benutzerdefinierte Codelogik implementieren, die auf ihre spezifischen Bedürfnisse zugeschnitten ist. Die Plattform umfasst Zeitleistenansichten mit Gantt-Diagrammen zur Identifizierung von Engpässen, Thread-Ansichten zum Debuggen von Multi-Turn-Konversationen und natürlichsprachgesteuerten Trace-Visualisierungen, die als Sandbox-React-Komponenten angezeigt werden. Es unterstützt auch die Durchführung mehrerer Versuche für jede Eingabe und hilft Teams so, die Varianz zu messen und die Konsistenz aufrechtzuerhalten.
Braintrust lässt sich reibungslos in führende KI-Frameworks integrieren und bietet native Unterstützung für 9+ wichtige Frameworks, wie OpenTelemetry, Vercel AI SDK, OpenAI Agent SDK, Instructor, LangChain, LangGraph, Google ADK, Mastra und Pydantic AI. Es wird ein „Wrap“ verwendet. Ansatz zur Integration – Beispiele hierfür sind wrapAISDK für Vercel AI SDK (für die Beta-Versionen v3 bis v6) und wrap_openai für Ausbilder. Die Plattform hält sich daran Semantische Konventionen von OpenTelemetry GenAI, wobei Details wie Token-Nutzung und Modell-IDs automatisch den Braintrust-Feldern zugeordnet werden. Es funktioniert nahtlos mit großen LLM-Anbietern, darunter OpenAI, Anthropic und Google Gemini. Entwickler können auch die verwenden Eval() Funktion oder die CLI mit dem --betrachten Flag, um Auswertungen automatisch erneut auszuführen, wenn Dateien während der Entwicklung aktualisiert werden.
Braintrust geht über die Bewertung hinaus, indem es die Teamzusammenarbeit mit integrierten Tools fördert. Es ist bidirektionale Synchronisation stellt sicher, dass Produktmanager und Ingenieure abwechselnd zwischen Code und Benutzeroberfläche an Eingabeaufforderungen arbeiten können. Der Spielplatz bietet einen Raum ohne Code, in dem Teams Eingabeaufforderungen testen, Modelle nebeneinander vergleichen und Konfigurationen für schnelle Iterationen teilen können. Spezielle Anmerkungstools ermöglichen es Teams, Human-in-the-Loop-Feedback zu geben und Beschriftungen oder Korrekturen direkt zu Spuren und Modellausgaben hinzuzufügen. Externe Annotatoren können eingeladen werden, die Qualität verschiedener Modellversionen zu bewerten, während gemeinsame Bewertungsrückstände Datensätze und Bewertungsrubriken zentralisieren, sodass keine manuelle Tabellenverfolgung erforderlich ist.
Phoenix von Arize AI ist eine Open-Source-Plattform, die Teams umfassende Kontrolle über die Auswertung großer Sprachmodelle (LLMs) geben soll. Phoenix basiert auf OpenTelemetry und hat mit über 2,5 Millionen Downloads und über 8.500 GitHub-Sternen Aufmerksamkeit erregt. Es bietet eine detaillierte Nachverfolgung, um jeden Schritt eines LLM-Workflows zu verfolgen und so leichter zu erkennen, wo Probleme auftreten.
Phoenix beschäftigt die LLM-als-Richter Ansatz, der Basismodelle von OpenAI, Anthropic und Gemini verwendet, um andere LLM-Anwendungen auf Faktoren wie Relevanz, Toxizität und Gesamtleistung zu bewerten. Es verfügt über vorgefertigte Evaluatoren für häufige Aufgaben wie Retrieval-Augmented Generation (RAG) und Funktionsaufrufe. Ein herausragendes Merkmal ist ErklärungsfähigkeitHier liefern Bewertungsmodelle eine klare Begründung für ihre Bewertungen und helfen Entwicklern, die Logik hinter jeder Bewertung zu verstehen. Zu den weiteren Tools gehören deterministische Code-basierte Prüfungen, menschliche Anmerkungen direkt innerhalb der Schnittstelle und Datensatz-Clustering das Einbettungen verwendet, um semantisch ähnliche Fragen und Antworten visuell zu gruppieren. Diese Clusterbildung hilft dabei, Bereiche zu isolieren, in denen Modelle eine unterdurchschnittliche Leistung erbringen.
__XLATE_63__
Diese Evaluierungstools lassen sich nahtlos in das breitere Entwicklungsökosystem der Plattform integrieren.
Phoenix unterstützt die automatische Instrumentierung für gängige Frameworks wie LlamaIndex, LangChain, DSPy, Mastra und Vercel AI SDK. Es funktioniert mit Python, TypeScript und Java und sein OpenTelemetry-natives Design gewährleistet die Kompatibilität mit vorhandenen Observability-Tools, ohne Benutzer an bestimmte Anbieter zu binden. Teams können auch Auswertungen aus Bibliotheken von Drittanbietern wie Ragas, Deepeval oder Cleanlab integrieren und so ihre Arbeitsabläufe flexibler gestalten.
Phoenix ist auf Effizienz und Leistung ausgelegt bis zu 20-mal schnellere Evaluierungsläufe durch Parallelität und Stapelverarbeitung. Der Prompt Playground bietet eine Testumgebung, in der Teams vor der Bereitstellung Eingabeaufforderungen verfeinern und Modellvarianten nebeneinander vergleichen können, wodurch das Risiko teurer Produktionsfehler verringert wird.
Als vollständig Open-Source- und selbsthostbare Plattform stellt Phoenix sicher, dass Teams die vollständige Kontrolle über ihre Daten behalten. Funktionen wie Warteschlangen für menschliche Anmerkungen ermöglichen das direkte Hinzufügen von Ground-Truth-Labels zu Spuren und fördern so eine bessere Zusammenarbeit. Der Prompt-Hub verwaltet die sofortige Versionierung, Speicherung und Bereitstellung in verschiedenen Umgebungen, während die Span-Chat Das Tool ermöglicht es Teams, bestimmte Workflow-Segmente zu bewerten und zu diskutieren, um Leistungsprobleme aufzudecken. Mit einer Slack-Community mit über 7.000 Mitgliedern haben Benutzer Zugriff auf ein Netzwerk zur Fehlerbehebung und zum Austausch von Erkenntnissen.
__XLATE_76__
LangSmith ist eine vielseitige Plattform, die nahtlos mit oder ohne LangChain funktioniert und sich somit an jeden LLM-Stack anpassen lässt. Es lässt sich mühelos mit Tools wie OpenAI, Anthropic, CrewAI, Vercel AI SDK und Pydantic AI verbinden und bietet Flexibilität für Teams, die bereits bestimmte Frameworks verwenden. Die Plattform erfüllt Compliance-Standards wie HIPAA, SOC 2 Typ 2 und DSGVO und verwendet einen asynchronen Prozess zum Senden von Traces, sodass für Endbenutzer keine zusätzliche Latenz entsteht.
LangSmith bietet zwei Auswertungsmodi um unterschiedlichen Anforderungen gerecht zu werden: Offline-Auswertung zum Testen kuratierter Datensätze während der Entwicklung und Online-Auswertung zur Überwachung des Live-Produktionsverkehrs. Es unterstützt vier Arten von Evaluatoren:
Die Plattform umfasst erweiterte Analysetools wie Diff-Ansicht, das Unterschiede zwischen Modellausgaben und Referenztexten sowie direkte Vergleiche für Leistungsbenchmarking hervorhebt. Es bietet auch Gruppierung von MetadatenDies ermöglicht die Analyse von Metriken wie Genauigkeit oder Kosten nach Kategorien wie Themenbereich oder Benutzertyp. LangSmith lässt sich in Open Source integrieren openevals Paket, das vorgefertigte Evaluatoren zur Beurteilung von Korrektheit und Kürze bietet.
Diese Funktionen erleichtern die Integration von LangSmith in bestehende Arbeitsabläufe und Entwicklungstools.
LangSmith vereinfacht die Nachverfolgung mit dem @traceable Decorator- oder Client-Wrapper, die Ein- und Ausgaben automatisch erfassen. Es unterstützt die Integration mit Python- und TypeScript/JavaScript-SDKs, einer REST-API und Test-Frameworks wie Pytest, Vitest und Jest und erleichtert so die Einbettung von Auswertungen in CI/CD-Pipelines. Darüber hinaus ermöglicht die OpenTelemetry-Integration Teams, Traces von bestehenden Observability-Pipelines direkt an LangSmith zu senden.
LangSmith verbessert die Teamzusammenarbeit mit intuitiven Feedback- und Anmerkungstools. Anmerkungswarteschlangen Ermöglichen Sie die automatische Weiterleitung bestimmter Läufe an Fachexperten zur manuellen Überprüfung und Bewertung auf der Grundlage benutzerdefinierter Kriterien. Der Prompt-Hub dient als zentraler Bereich für Teams zur Iteration, Versionierung und Freigabe von Eingabeaufforderungen, komplett mit Änderungsverfolgungs- und Rollback-Funktionen, um die Konsistenz während der gesamten Entwicklung aufrechtzuerhalten. Mit Inline-Anmerkungsfunktionen können Teammitglieder Probleme kennzeichnen oder gezieltes Feedback zur Antwortqualität geben, wodurch sowohl die Genauigkeit der Bewertung als auch die Effizienz des Arbeitsablaufs verbessert werden.
Die Plattform bietet außerdem eine detaillierte Benutzerverwaltung und Workload-Isolierung und gewährleistet so eine reibungslose Zusammenarbeit zwischen Teams. Benutzer können sich kostenlos unter smith.langchain.com anmelden – keine Kreditkarte erforderlich. Für den Produktionseinsatz arbeitet LangSmith auf Pay-as-you-go-Basis, wobei Unternehmenspläne für Selbsthosting auf Kubernetes-Clustern in AWS, GCP oder Azure verfügbar sind.
Bei der Bewertung von Plattformen für die LLM-Bewertung ist es wichtig, technische Kompatibilität, Kosten und Bewertungsmethoden zu berücksichtigen. Hier ist ein genauerer Blick auf die Optionen:
Prompts.ai vereint mehr als 35 führende Modelle unter einer sicheren Schnittstelle und bietet FinOps-Kontrollen, die die Kosten für KI-Software um bis zu 98 % senken können. Braintrust Vereinfacht die Einrichtung mit einem AI-Proxy ohne Konfiguration, der Protokolle über eine einzige Basis-URL erfasst. Es beinhaltet 1 Million Trace-Spans kostenlos, wobei kostenpflichtige Pläne bei 249 $/Monat beginnen. Maxim AI lässt sich nahtlos in bestehende Observability-Stacks integrieren und konzentriert sich auf die Qualitätsbewertung statt auf die vollständige Nachverfolgung. Es bietet einen kostenlosen Plan für bis zu 10.000 Protokolle pro Monat und kostenpflichtige Pläne ab 29 $ pro Sitzplatz/Monat. Arize Phoenix unterstützt Selbsthosting für den Datenschutz und lässt sich für eine tiefergehende Metrikanalyse in Tools wie RAGAS und Giskard integrieren. LangSmith ist auf LangChain-Benutzer zugeschnitten und bietet erweiterte Observability, allerdings variieren die Preise für den Unternehmenssupport. Bemerkenswert ist, dass Notion mit Braintrust seine Entwicklungsgeschwindigkeit verzehnfachte und von 3 Problemen pro Tag auf 30 anstieg.
Der einzigartige Ansatz jeder Plattform vereinfacht die Entscheidungsfindung basierend auf Ihren spezifischen Bewertungsanforderungen. So vergleichen sie sich in Bezug auf Evaluierungsmethoden, Integration und Bereitstellung:
Auch die Integrationskomplexität spielt eine Schlüsselrolle. Die Proxy-basierte Einrichtung von Braintrust ist unkompliziert – aktualisieren Sie einfach Ihre API-Basis-URL. Maxim AI lässt sich in bestehende Observability-Tools integrieren, während die enge LangChain-Integration von LangSmith spezielle Observability-Anforderungen erfüllt. Arize Phoenix zeichnet sich durch Unternehmen aus, die der Datensouveränität Priorität einräumen, und bietet eine selbst gehostete Open-Source-Lösung. Unterdessen bietet Prompts.ai unternehmenstaugliche Governance-Kontrollen und vollständige Audit-Trails für einen sicheren Betrieb.
__XLATE_111__
Für schnelle Erkenntnisse optimieren Proxy-basierte Bereitstellungen und umfassende Integrationen den Prozess. LangChain-Benutzer werden LangSmith als natürliche Ergänzung empfinden, während Unternehmen, die sensible Daten verwalten, möglicherweise auf Open-Source-Lösungen wie Arize Phoenix oder Prompts.ai zurückgreifen, um robuste Governance- und Prüffunktionen zu erhalten.
Basierend auf den bereitgestellten Auswertungen bietet jede Plattform eindeutige Vorteile für die Verfeinerung der LLM-Output-Analyse. Prompts.ai bietet Unternehmen einen zentralen Zugriff auf führende Modelle, gepaart mit FinOps-Kontrollen, die die KI-Kosten um bis zu 98 % senken können und gleichzeitig robuste Governance- und Audit-Funktionen gewährleisten. Braintrust ist auf schnelllebige Entwicklungsteams zugeschnitten. Unternehmen wie Notion berichten von einer 10-fachen Steigerung der Entwicklungsgeschwindigkeit und einer Steigerung der Problemlösung von 3 auf 30 pro Tag. In ähnlicher Weise beobachteten die Teams von Stripe und Airtable innerhalb weniger Wochen nach der Einführung der Plattform eine Genauigkeitssteigerung von über 30 %.
Für diejenigen, die tief in das LangChain-Ökosystem integriert sind: LangSmith bietet mühelose Integration und schnelle Prototyping-Optionen. Maxim AI richtet sich an Teams, die sich auf die Verwaltung komplexer Multiagentensysteme konzentrieren, und bietet präzise Bewertungstools und ein Gateway mit geringer Latenz, das bei einem Volumen von 5.000 Anfragen pro Sekunde nur 11 Mikrosekunden Overhead verursacht. In der Zwischenzeit, Arize Phoenix ist ideal für Organisationen, die der Datensouveränität Priorität einräumen, und bietet eine selbst gehostete Open-Source-Lösung, die sich nahtlos in bestehende Observability-Systeme einfügt.
Jede Plattform befasst sich mit kritischen Herausforderungen bei der LLM-Leistung und dem Kostenmanagement. Da Unternehmen mit potenziellen Verlusten konfrontiert sind 1,9 Milliarden US-Dollar pro Jahr Aufgrund unentdeckter LLM-Fehler in der Produktion ist die Notwendigkeit, über subjektive Bewertungen hinaus zu messbaren, datengesteuerten Metriken überzugehen, für die Gewährleistung von Zuverlässigkeit und Effizienz unerlässlich geworden.
Diese Tools machen die LLM-Entwicklung zu einer strukturierten Ingenieursdisziplin. Ganz gleich, ob Sie sich auf die Bearbeitung von Billionen von Ereignissen pro Monat, die Optimierung der teamübergreifenden Zusammenarbeit oder die Kontrolle über die selbst gehostete Infrastruktur konzentrieren: Die Wahl der richtigen Plattform stellt sicher, dass Ihre LLM-Workflows die Zuverlässigkeit, Qualität und Kosteneffizienz erreichen, die Sie zum Erreichen Ihrer Ziele benötigen.
Diese Plattformen sollen Unternehmen dabei helfen, ihre KI-Kosten zu senken, indem sie Tools zur Überwachung und Feinabstimmung der Verwendung großer Sprachmodelle (LLMs) anbieten. Lösungen wie Prompts.ai ermöglichen es Benutzern beispielsweise, die Token-Nutzung in Echtzeit zu verfolgen, wodurch unnötiger Token-Verbrauch leichter erkannt und reduziert werden kann. Dies trägt dazu bei, zu hohe Ausgaben für übermäßige API-Aufrufe zu vermeiden, was zu einem besseren Kostenmanagement führt.
Über die Kostenkontrolle hinaus bieten diese Plattformen auch wertvolle Einblicke in die Leistung und Ausgabequalität. Sie können dabei helfen, Probleme wie Halluzinationen oder Fehler zu erkennen und zu verhindern, die andernfalls zu kostspieligen Nacharbeiten führen könnten. Durch die Analyse von Nutzungstrends und die Ermittlung von Ineffizienzen können Unternehmen Arbeitsabläufe optimieren, Betriebskosten senken und konsistente, qualitativ hochwertige Ergebnisse sicherstellen. All dies unterstützt intelligentere, datengesteuerte Entscheidungen zur effektiven Verwaltung von KI-Budgets.
LLM-Plattformen bieten verschiedene Möglichkeiten, sich nahtlos mit Tools und Arbeitsabläufen zu verbinden und so unterschiedlichen Anforderungen gerecht zu werden. Viele Plattformen unterstützen die native Integration über SDKs wie Python und JavaScript sowie Frameworks wie LangChain und LangServe. Dies macht die Einbettung von LLMs in benutzerdefinierte Anwendungen einfach und effizient. Für die Überwachung unterstützen Plattformen oft offene Standards wie OpenTelemetry und stellen so die Kompatibilität mit der bestehenden Infrastruktur sicher.
Einige Plattformen lassen sich auch mit CI/CD-Tools wie GitHub Actions und Jenkins integrieren und vereinfachen so Test- und Bereitstellungsprozesse. Für Organisationen, die die Kontrolle über ihre Umgebung priorisieren, stehen Self-Hosting-Optionen zur Verfügung, die eine individuelle Anpassung bei gleichzeitiger Wahrung der Datensicherheit ermöglichen. Diese Integrationsfunktionen ermöglichen es Benutzern, die Effizienz zu steigern, die Leistung effektiv zu überwachen und LLMs sicher in ihren Betrieben zu implementieren.
Für diejenigen, die Wert darauf legen Datenschutz und Kontrolle, OnPrem.LLM liefert eine hervorragende Lösung. Diese Plattform wurde speziell für datenschutzrelevante Aufgaben entwickelt und ermöglicht großen Sprachmodellen (LLMs), vertrauliche oder eingeschränkte Daten sicher in Offline-Umgebungen zu verarbeiten. Durch die Möglichkeit einer vollständig lokalen Ausführung wird das Risiko einer Datenoffenlegung erheblich reduziert und bei Bedarf auch eine optionale Cloud-Integration für Hybrid-Setups angeboten.
Mit seiner intuitiven Benutzeroberfläche ohne Code gewährleistet OnPrem.LLM die Zugänglichkeit für Benutzer ohne technisches Fachwissen und behält gleichzeitig den vollständigen Überblick über die Datenverwaltung. Dies macht es zur idealen Wahl für Unternehmen in regulierten oder sensiblen Branchen, in denen der Schutz von Informationen oberste Priorität hat.



















