Nutzungsbasierte Abrechnung - AI Model Orchestration and Workflows Platform

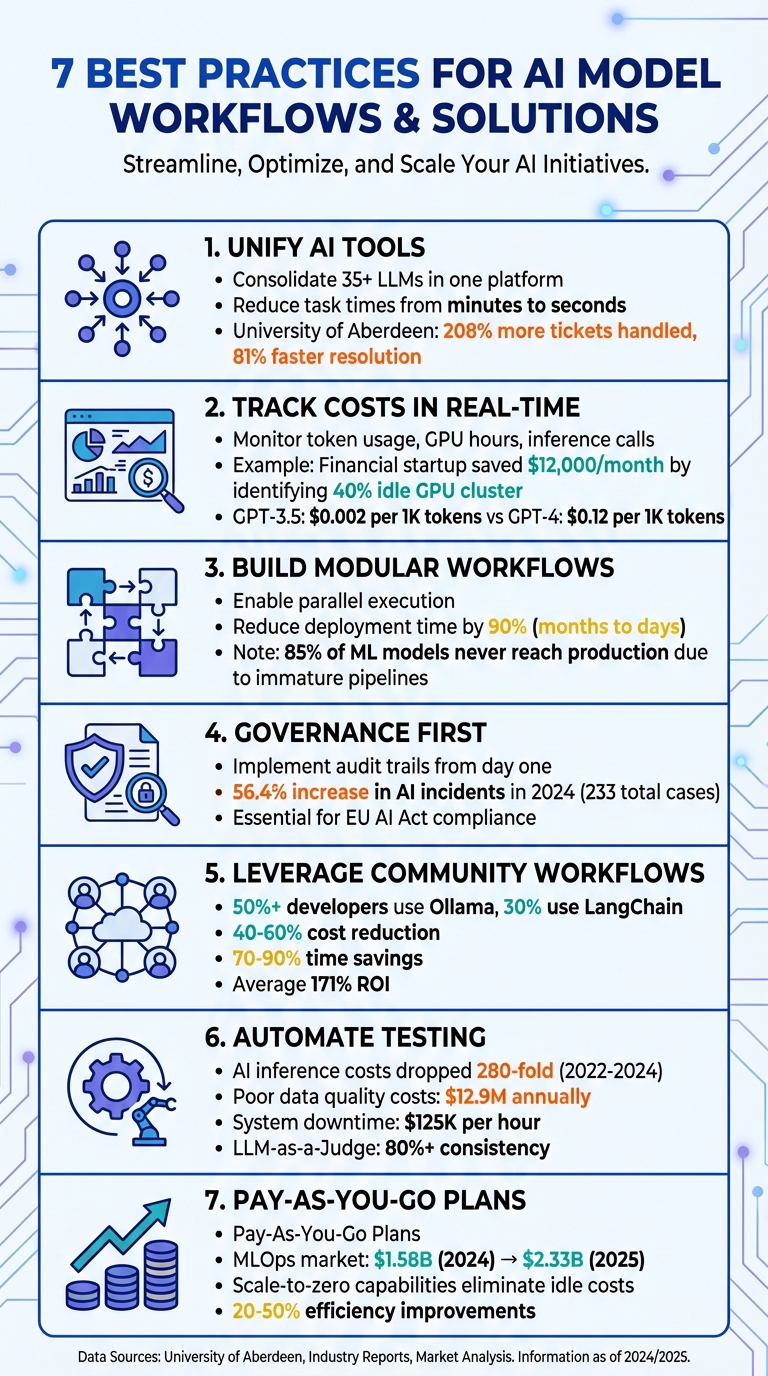
AI workflows in 2026 face challenges like fragmented tools, unchecked model drift, and escalating costs. To overcome these, organizations are adopting smarter, automated workflows that unify tools, improve governance, and optimize spending. Here’s how you can transform your AI operations:
Diese Praktiken rationalisieren Arbeitsabläufe, verbessern die Übersicht und senken die Kosten, sodass Unternehmen die KI verantwortungsvoll und effizient skalieren können.
__XLATE_1__
Die Verwaltung separater Plattformen für Modelle wie GPT-5, Claude, LLaMA und Gemini kann den Betrieb verlangsamen und unnötige Hürden schaffen. Durch die Konsolidierung von über 35 LLMs in einer Schnittstelle eliminiert Prompts.ai den Aufwand des Jonglierens mit mehreren Anmeldungen und Anmeldeinformationen und reduziert die Aufgabenzeit von Minuten auf nur noch Sekunden.
Diese Art der Integration führt zu messbaren Produktivitätssteigerungen. Als beispielsweise die University of Aberdeen im September 2025 ein KI-gestütztes System einführte, konnte ihr IT-Team 208 % mehr Tickets bearbeiten und gleichzeitig die Lösungszeiten um 81 % verkürzen [1]. Solche Ergebnisse verdeutlichen, wie ein optimiertes System es Teams ermöglicht, sich auf Ergebnisse zu konzentrieren, anstatt Zeit mit der Verwaltung fragmentierter Tools zu verschwenden. Dieser Ansatz ebnet den Weg für effizientere, zuverlässigere und kostengünstigere KI-Workflows.
Eine einheitliche Schnittstelle spart nicht nur Zeit, sondern sorgt auch für mehr Zuverlässigkeit und Flexibilität. Da alle Modelle von einer einzigen Plattform aus zugänglich sind, können Teams nahtlos zwischen Engines wechseln und so die Kontinuität gewährleisten, selbst wenn ein Modell ausfällt oder ungenaue Ergebnisse liefert. Dieses proaktive Setup verhindert außer Kontrolle geratene Prozesse, die zu explodierenden Cloud-Kosten führen können, wenn automatisierte Agenten ohne angemessene Kontrollen in der Schleife arbeiten.
Die Plattform ermöglicht auch parallele Leistungstests, sodass Sie bewerten können, welches Modell am besten für bestimmte Aufgaben geeignet ist. Beispielsweise könnten Kundensupportanfragen an ein LLM weitergeleitet werden, kreative Projekte an ein anderes und die Datenverarbeitung an ein drittes – alles über dasselbe Dashboard verwaltet. Dieses modellunabhängige Design stellt sicher, dass Sie nicht an die Einschränkungen oder Preise eines einzelnen Anbieters gebunden sind und gibt Ihnen die Freiheit, Leistung und Kosten zu optimieren.
Prompts.ai bringt das Kostenmanagement auf die nächste Ebene, indem es Echtzeit-Einblicke in die Token-Nutzung über alle Modelle hinweg bietet. Diese Transparenz trägt dazu bei, Budgetüberschreitungen zu verhindern, bevor sie auftreten. Eine integrierte FinOps-Ebene verfolgt die Ausgaben auf der Prompt-Ebene und erleichtert so die Identifizierung, welche Arbeitsabläufe einen Mehrwert liefern und welche Ressourcen verbrauchen. Unternehmen, die KI-Workflow-Automatisierung nutzen, haben einen ROI von 84 % gemeldet, wenn sie Ausgaben mit Geschäftsergebnissen verknüpfen können. Databricks beispielsweise reduzierte die Support-Tickets um 23 % durch intelligentes Triaging, das auf sauberen Datenmodellen und transparenter Kostenverfolgung basiert [1].
Durch die nutzungsabhängigen TOKN-Gutschriften der Plattform werden die Ausgaben an die tatsächliche Nutzung angepasst, sodass keine Zahlungen für ungenutzte Kapazitäten erforderlich sind. Durch die Konsolidierung der Kosten über mehrere Modelle hinweg können Teams im Vergleich zur Aufrechterhaltung separater Abonnements für jedes Tool bis zu 98 % einsparen, was zu erheblichen Einsparungen über Projekte und Abteilungen hinweg führt.
Prompts.ai stärkt außerdem Governance und Compliance und bietet einheitliche Audit-Trails, die sowohl regulatorische Anforderungen als auch Workflow-Verbesserungen unterstützen. Die Plattform kategorisiert Aufgaben in Risikostufen und stellt so sicher, dass Vorgänge mit hohem Risiko (z. B. Aufgaben der Stufe 4 mit Katastrophenpotenzial) unter menschlicher Aufsicht bleiben, bis die KI-Systeme vollständig zuverlässig sind.
Mit Ende-zu-Ende-Verschlüsselung und strengen Zugriffskontrollen bleiben sensible Daten vor Fehlkonfigurationen oder Verstößen geschützt. Da mittlerweile 78 % der Unternehmen KI in mindestens einem Bereich ihres Geschäfts einsetzen [2], bietet Prompts.ai Sicherheit auf Unternehmensniveau und behält gleichzeitig die Geschwindigkeit und Agilität bei, die Teams für Innovationen benötigen. Jede Interaktion ist sicher, nachvollziehbar und überprüfbar, was Unternehmen die Sicherheit gibt, KI verantwortungsvoll zu skalieren.
KI-Arbeitsbelastungen führen oft zu unvorhersehbaren Ausgaben, die anhand der monatlichen Rechnungen nicht vollständig nachvollzogen werden können. Echtzeit-FinOps ändert dies, indem es sofortige Einblicke in die anfallenden Kosten bietet. Durch die Verfolgung der Token-Nutzung, GPU-Stunden und Inferenzaufrufe nahezu in Echtzeit können Teams Budgetüberschreitungen erkennen und beheben, bevor sie außer Kontrolle geraten.
Ein Finanzanalyse-Startup stellte beispielsweise fest, dass 40 % seines 8-GPU-Clusters im Leerlauf waren und jeden Monat fast 12.000 US-Dollar verschwendeten. Durch Echtzeitüberwachung erkannte das Team diese Ineffizienz mitten im Sprint und nahm Anpassungen vor, um die Kapazität sofort zu optimieren.
Die detaillierte Nachverfolgung nach Team, Projekt oder Kunde verfeinert die Rückbuchungsmodelle weiter. Durch das Anhängen von Metadaten wie Kunden-IDs an API-Anfragen werden die Ausgaben transparenter. Dadurch können Abteilungen nur für das zahlen, was sie nutzen, und ebnen so den Weg für skalierbare und kosteneffiziente Abläufe.
Real-time tracking doesn’t just monitor costs - it actively supports smarter scaling decisions. Autoscaling can now factor in both performance metrics (like latency) and financial data (such as cost per prediction). For example, during traffic spikes, systems can throttle or reroute requests based on cost signals, ensuring resources are used efficiently.
__XLATE_13__
StreamForge AI hat diese Strategie im September 2025 übernommen, indem Kubecost mit Prometheus integriert wurde und Nutzungsdaten auf Grafana-Dashboards angezeigt wurden, die alle fünf Minuten aktualisiert wurden. Mithilfe eines Dual-Signaling-Autoscaling-Ansatzes, der p95-Latenz und Kosten-pro-Anfrage-Metriken in Einklang bringt, steigerten sie die GPU-Auslastung erheblich und verbesserten die Kosteneffizienz von über 300 täglichen Trainingsjobs. Dieser Echtzeitansatz trägt dazu bei, kostspielige Fehlkonfigurationen zu vermeiden, die das monatliche Budget belasten könnten.
Centralizing cost tracking across multiple AI providers is essential when managing diverse models. A unified AI gateway simplifies this process by consolidating token usage, latency, and cost data into a single, reliable source. Whether you’re using OpenAI, Anthropic, or self-hosted models, this centralized system eliminates the need to piece together fragmented billing data.
Dieser Integrationsgrad ist von entscheidender Bedeutung, da verschiedene Modelle sehr unterschiedliche Preise haben. GPT-3.5-Turbo kostet beispielsweise etwa 0,002 US-Dollar pro 1.000 Token, während GPT-4 je nach Kontextfenster bis zu 0,12 US-Dollar pro 1.000 Token kosten kann. Die Echtzeitverfolgung ermöglicht es Teams, diese Kosten zu vergleichen und Aufgaben mit dem wirtschaftlichsten Modell weiterzuleiten. Ganz gleich, ob es sich um die Bearbeitung einfacher Kundenanfragen oder komplexer Analysen handelt: Aufgaben werden anhand von Live-Kostendaten dem richtigen Modell zugewiesen, sodass die Arbeitsabläufe sowohl effizient als auch budgetfreundlich bleiben.
Die Aufteilung von KI-Workflows in modulare Komponenten revolutioniert die Art und Weise, wie sie bereitgestellt und skaliert werden. Anstatt sich auf eine einzige, starre Pipeline zu verlassen, um jede Phase zu bewältigen, ermöglicht ein modularer Ansatz die Aktualisierung oder den Austausch einzelner Teile, ohne das gesamte System zu stören.
Dieses Design ermöglicht auch eine parallele Ausführung, bei der mehrere Aufgaben gleichzeitig ausgeführt werden können. Beispielsweise kann ein mehrsprachiger Übersetzungsdienst verschiedene Sprachversionen gleichzeitig und nicht nacheinander verarbeiten, was die Bearbeitungszeit erheblich verkürzt. Die Einführung von MLOps-Praktiken beschleunigt die Bereitstellung weiter und verkürzt die Zeit für die Überführung eines Modells in die Produktion um bis zu 90 %. Automatisierte Pipelines können die Bereitstellungszeiträume von Monaten auf nur wenige Tage verkürzen.
Ein weiterer Vorteil ist die Wiederspielbarkeit. Wenn bei einem bestimmten Schritt, z. B. der Nachbearbeitung, ein Problem auftritt, können Sie nur dieses Modul mit gespeicherten Artefakten erneut ausführen, anstatt den gesamten Workflow zu wiederholen. Dieser gezielte Wiederholungsansatz spart sowohl Zeit als auch Ressourcen, insbesondere bei Aufgaben, die eine erhebliche Rechenleistung erfordern. Modulare Arbeitsabläufe erleichtern außerdem die Standardisierung und sichere Integration von Komponenten im gesamten System.
Sobald eine modulare Grundlage geschaffen ist, ist die Gewährleistung einer reibungslosen Kommunikation zwischen den Komponenten von entscheidender Bedeutung. Durch die Standardisierung von Eingabe- und Ausgabeformaten können kaskadierende Fehler vermieden werden. Wenn beispielsweise ein Datenaufnahmemodul eine klar definierte JSON-Datei ausgibt, die perfekt mit der erwarteten Eingabe eines Inferenzmoduls übereinstimmt, werden potenzielle Fehlkommunikationen vermieden.
Durch die Trennung der KI-Logik von der Richtlinienlogik wird die Wartbarkeit weiter verbessert. Dadurch können Sie das dynamische Modellverhalten unabhängig von festen Geschäftsregeln verwalten, wie in den AWS Prescriptive Guidance hervorgehoben. Tools wie Docker oder Kubernetes können Module containerisieren und so sicherstellen, dass sie in verschiedenen Umgebungen portierbar bleiben. Ein Containermodul kann in Entwicklung, Staging und Produktion konsistent betrieben werden und sogar zwischen Cloud-Anbietern wechseln, ohne dass Änderungen erforderlich sind. Für die Orchestrierung bieten AWS Step Functions eine serverlose Koordination mit integrierten Wiederholungsversuchen, während Apache Airflow Python-basierte Flexibilität für die Verwaltung komplexerer Arbeitsabläufe bietet.
Modulare Designs bieten auch finanzielle Vorteile, da Sie jeder Aufgabe die richtigen Ressourcen zuweisen können. Komplexe, ressourcenintensive Argumentationsmodelle können für anspruchsvolle Analysen reserviert werden, während einfachere Aufgaben von kostengünstigeren Modellen übernommen werden. Dadurch wird sichergestellt, dass die Rechenressourcen sinnvoll genutzt werden.
Die Verfolgung von Metadaten auf Modulebene erhöht die Transparenz. Durch das Anhängen von Details wie Zeitstempeln, Modellversionen und Kostendaten an jedes Artefakt, während es sich durch die Pipeline bewegt, erhalten Teams einen klaren Prüfpfad. Dies hilft nicht nur beim Debuggen, sondern auch bei der Finanzverfolgung. Die Ausrichtung der Kosten an modulspezifischen Kennzahlen ermöglicht eine präzise Budgetierung bei gleichzeitiger Wahrung der Flexibilität. Darüber hinaus kann das Festlegen von Beschränkungen für Batch-Größen und Parallelität dazu beitragen, unerwartete Kosten in Zeiten hoher Nachfrage zu vermeiden.
It’s worth noting that about 85% of machine-learning models never make it to production, often due to immature pipeline structures. Modular, iterative workflows offer a way to overcome this challenge. Teams can start small, validate one module at a time, and gradually scale up, reducing risks and ensuring systems are ready for production.
Wenn Sie die Governance von Anfang an in Ihren KI-Workflow integrieren, ersparen Sie sich später kostspielige Anpassungen. Indem Sie auf den zuvor besprochenen automatisierten Auswertungen und der Transparenz aufbauen, können Sie sicherstellen, dass Compliance von Anfang an in Ihre Prozesse integriert ist. Sobald ein Modell oder Anwendungsfall erstellt wird, Erstellen Sie ein Tracking-Ticket in Ihrem Workflow-Tool und weisen Sie eine anfängliche Risikostufe zu. Anwendungen mit hohem Risiko, wie etwa Kreditbewertungs- oder Einstellungssysteme, erfordern im Vergleich zu intern verwendeten Tools mit geringerem Risiko strengere Genehmigungsprozesse und eine genauere Überwachung. Diese proaktive „Verschiebung nach links“ Mit diesem Ansatz sind Sie auf regulatorische Anforderungen vorbereitet, insbesondere wenn Rahmenwerke wie das EU-KI-Gesetz eine detaillierte Dokumentation von Schulungs- und Bewertungsprozessen vorschreiben.
Ein Eckpfeiler der Compliance ist Abstammungsverfolgung, das einen klaren und reproduzierbaren Weg von den Rohdaten bis zur endgültigen Modellausgabe bietet. Kombinieren Sie die Abstammungsverfolgung mit Snapshot-Rückverfolgbarkeit, um sicherzustellen, dass der genaue Status Ihres Codes, Ihrer Daten und Konfigurationen vor der Bereitstellung erhalten bleibt. Dadurch ist es möglich, jede Modellversion nach Bedarf zu reproduzieren. Branchenuntersuchungen unterstreichen die Dringlichkeit dieser Maßnahmen und stellen einen Anstieg der KI-bezogenen Vorfälle im Jahr 2024 um 56,4 % auf insgesamt 233 Fälle fest – was die Notwendigkeit robuster Prüfpfade unterstreicht.
Audit-Trails optimieren die Fehlerbehebung, indem sie Fehler direkt mit ihrer Ursache verknüpfen. Anstatt Protokolle manuell zu durchsuchen, können Ingenieure mithilfe der Herkunftsverfolgung schnell erkennen, wo eine Pipeline ausgefallen ist oder die Datenqualität nachgelassen hat. Die Automatisierung von Governance-Aufgaben – wie Bestandsprüfungen und Risikobewertungen – gewährleistet nicht nur die Einhaltung von Vorschriften, sondern sorgt auch dafür, dass Ihre KI-Initiativen bei ihrem Wachstum effizient voranschreiten. Durch die Automatisierung dieser Schritte können Sie die Genehmigungszeiten verkürzen und die Konsistenz über alle Abläufe hinweg gewährleisten.
Eine starke Datenverwaltung ist für die Aufrechterhaltung hochwertiger Daten unerlässlich. Die zentralisierte Metadatenverwaltung konsolidiert Informationen über alle KI-Assets an einem Ort, beseitigt Redundanzen und sorgt für einen reibungslosen Betrieb. Wenn jede Komponente, von Eingabeaufforderungen bis hin zu Modellversionen, mit Zeitstempeln und Kostendetails verfolgt wird, gewinnen Teams einen Vorteil umfassende Ausführungsgeschichte. Dadurch lassen sich Pipelines einfacher reproduzieren und verfeinern. Automatisierte Prüfprotokolle reduzieren menschliche Fehler weiter und sorgen für einen zuverlässigen und wiederholbaren Arbeitsablauf.
Diese Governance-Strategien lassen sich nahtlos in modulare Arbeitsabläufe integrieren und stellen sicher, dass Compliance auch bei der Skalierung ein zentraler Bestandteil Ihres Systems bleibt.
Eine einheitliche Governance-Ebene verbindet optimierte Arbeitsabläufe und Kostentransparenz und sorgt so für Compliance auf ganzer Linie. Viele Systeme – wie Snowflake, Databricks, Cloud-Plattformen und Edge-Umgebungen – arbeiten plattformübergreifend. Ohne einen einheitlichen Governance-Ansatz besteht die Gefahr einer „Schatten-KI“, bei der Modelle ohne Aufsicht bereitgestellt werden, was eine Compliance-Überprüfung unmöglich macht. Systemübergreifende Rückverfolgbarkeit stellt sicher, dass die Herkunft der Laufzeitdaten über Abfragen, Notebooks, Jobs und Dashboards hinweg erfasst wird, und sorgt so für die Einhaltung der Compliance, wenn Daten zwischen Plattformen verschoben werden. Standardisierte Schnittstellen wie das Model Context Protocol (MCP) mit zentralisierten Gateways ermöglichen eine konsistente Protokollierung und Anforderungsverfolgung über Server und Mandanten hinweg. Dadurch erhalten Sie einen vollständigen Audit-Trail, unabhängig davon, wo die Arbeit stattfindet.
Das Erstellen von Arbeitsabläufen von Grund auf kann zeitaufwändig und ineffizient sein. Community-gesteuerte Frameworks wie LangChain Und Ollama sind zu bevorzugten Lösungen geworden und bieten vorgefertigte Vorlagen für die Verkettung von Eingabeaufforderungen und die Integration von Tools. Diese Frameworks sind weit verbreitet: Über 50 % der Entwickler verwenden Ollama und fast ein Drittel verlässt sich bei der Verwaltung von KI-Agenten auf LangChain. Sie ersetzen fragilen benutzerdefinierten Code durch flexible, serverlose Funktionen, die unabhängig voneinander funktionieren, wodurch sie einfacher zu verwalten und zu skalieren sind.
Der Hauptvorteil ist Skalierbarkeit ohne Komplexität. Indem Sie sich auf von der Community getestete Muster verlassen, können Sie Modelle wechseln – beispielsweise von GPT zu Amazon Bedrock –, ohne Ihre Orchestrierungslogik zu überarbeiten. Diese Flexibilität beschleunigt die Bereitstellung und sorgt gleichzeitig für Konsistenz. Untersuchungen zeigen, dass die Orchestrierung zwar für viele Organisationen Priorität hat, diese jedoch nur wenige vollständig implementiert haben. Community-Workflows bieten eine praktische Lösung und ermöglichen eine nahtlose Integration über verschiedene KI-Plattformen hinweg.
Community-Workflows befassen sich auch mit der Herausforderung, KI-Tools plattformübergreifend zu integrieren. Standards wie die Model Context Protocol (MCP) Beheben Sie das Problem der Plattformausbreitung, ein Problem für 63 % der Führungskräfte. Mithilfe dieser Protokolle können KI-Agenten und -Tools plattformübergreifend wie Gmail, Slack und CRMs zusammenarbeiten, ohne dass eine manuelle Dateneingabe erforderlich ist. Beispielsweise kann eine einfache Anfrage in natürlicher Sprache wie „Zusammenfassen der letzten 10 E-Mails von Gmail“ verwendet werden. - kann strukturierte Aufgaben mit vorkonfigurierten API-Verbindungen auslösen.
__XLATE_52__
Interoperabilität ist von entscheidender Bedeutung 87 % der IT-Führungskräfte Identifizieren Sie es als wesentlich für die Einführung KI-gesteuerter Systeme. Community-Workflows sind auf Ausfallsicherheit ausgelegt und bieten Funktionen wie automatische Wiederholungsversuche, Zeitüberschreitungen und parallele Ausführung zur Bewältigung potenzieller Modellfehler. Diese Schutzmaßnahmen sind insbesondere deshalb von entscheidender Bedeutung 87 % der Entwickler machen sich Sorgen um die Genauigkeit der KI, Und 81 % sind besorgt über Sicherheit und Datenschutz. Diese Arbeitsabläufe verbessern nicht nur die Integration, sondern tragen auch dazu bei, die Kosten erheblich zu senken.
Durch die Verwendung von Community-Vorlagen zur Umwandlung von Eingabeaufforderungen in natürlicher Sprache in automatisierte Arbeitsabläufe können Kosten drastisch gesenkt und Zeit gespart werden. Organisationen berichten 40–60 % Kostensenkung Und 70–90 % Zeitersparnis wenn sie die KI-Automatisierung durch diese Arbeitsabläufe übernehmen. Wenn Sie mit getesteten Lösungen beginnen, entfallen teure Versuch-und-Irrtum-Prozesse.
Diese Arbeitsabläufe erhöhen auch die Transparenz, indem sie standardisierte Audit-Trails und Metadatenverfolgung integrieren. Sie protokollieren automatisch Details wie Datenquellen, Berechtigungen und Entscheidungshistorien der Agenten. Viele beinhalten Mensch-in-the-Loop Kontrollpunkte für die manuelle Überprüfung sensibler oder kostenintensiver Aufgaben, um die Kontrolle dort sicherzustellen, wo es am wichtigsten ist. Durch die Verwaltung der Inferenzkosten während der Skalierung haben Unternehmen einen Durchschnitt erzielt 171 % ROI bei der Nutzung von Community-Workflows.
Die Automatisierung von Tests und Auswertungen ist der letzte Schritt bei der Schaffung eines nahtlosen KI-Lebenszyklus. Es eliminiert die durch manuelle Tests verursachten Verzögerungen, die oft verhindern, dass Modelle in die Produktion gelangen – 85 % der Modelle werden aufgrund von Prozessineffizienzen nicht bereitgestellt. Durch die Nutzung automatisierter CI/CD/CT-Pipelines (Continuous Training) verkürzen sich die Bereitstellungszeiten von Monaten auf nur wenige Tage. Diese Pipelines können Modelle automatisch neu trainieren, wenn die Leistungsmetriken unter festgelegte Schwellenwerte fallen oder wenn neue Daten verfügbar werden, sodass keine ständige manuelle Überwachung erforderlich ist.
Die finanziellen Vorteile liegen auf der Hand. Zwischen 2022 und 2024 sind die Kosten für KI-Inferenz um das 280-fache gesunken, sodass kontinuierliche Überwachung und Umschulung eine praktische Option sind. Automatisierte Pipelines helfen außerdem dabei, Probleme frühzeitig zu erkennen und kostspielige Fehler zu vermeiden. Beispielsweise kann eine schlechte Datenqualität Unternehmen jährlich 12,9 Millionen US-Dollar kosten, während ungeplante Systemausfallzeiten 125.000 US-Dollar pro Stunde erreichen können. Automatisierte Datenvalidierungsschritte, wie die Identifizierung von Schemakonflikten, Nullwerten oder Verteilungsverschiebungen, stellen sicher, dass Probleme bereits in der Aufnahmephase behoben werden, und verhindern so später größere Probleme.
Automatisierung beschleunigt nicht nur Arbeitsabläufe, sondern reduziert auch unnötige Kosten. Selbstanpassende Pipelines stellen sicher, dass eine Neuschulung nur bei Bedarf erfolgt, wodurch die Nutzung teurer GPU-Ressourcen in Leerlaufzeiten reduziert wird. Tools wie LLM-as-a-Judge optimieren Bewertungsprozesse, senken die Kosten und gewährleisten gleichzeitig eine Konsistenz von über 80 % über Tausende von Tests hinweg.
Teststrategien können die Budgets weiter optimieren. Durch die Simulation von Tests mit Tools wie Dev Proxy können Sie Endpunkte einem Stresstest unterziehen, ohne dass Gebühren pro Anruf anfallen. Wenn Sie mit kleineren Modellen und repräsentativen Datensätzen beginnen, können Sie Ideen validieren, bevor Sie sich auf umfassende Auswertungen festlegen. Darüber hinaus bietet die Kennzeichnung von Cloud-Ressourcen nach Projekt, Team oder Modellversion detaillierte Einblicke in die Abrechnung und erleichtert so die Entscheidung, welche Arbeitsabläufe die Investition wert sind.
Automatisierte Tests stärken auch die Governance, indem sie die von den Aufsichtsbehörden geforderten Audit-Trails erstellen. Governance-Gates sorgen dafür, dass Arbeitsabläufe angehalten werden, bis kritische Assets – wie Schemata und Basisdaten – validiert sind. Jeder Modell-Snapshot wird einer standardmäßigen Risikobewertung unterzogen, wobei die Ergebnisse automatisch protokolliert und bei Fehlern Tickets zur Nachverfolgung ausgestellt werden.
Die Automatisierung kann drei Hauptarten von Abweichungen überwachen: Datendrift (Verschiebungen der Eingabeverteilungen), Leistungsdrift (Abnahme der Genauigkeit oder langsamere Reaktionszeiten) und Sicherheitsdrift (erhöhte Toxizität oder Offenlegung sensibler Informationen). Durch Warnungen wird auf diese Probleme frühzeitig hingewiesen und verhindert, dass sie sich auf Endbenutzer auswirken. Darüber hinaus ermöglichen Kill-Switches Teams, bei Vorfällen problematische Modellrouten oder -funktionen schnell zu deaktivieren und so einen praxisorientierten Governance-Ansatz zu demonstrieren, der sicherstellt, dass Systeme unter Kontrolle bleiben, wenn es darauf ankommt.
Pay-as-you-go-Pläne sind eine intelligente Möglichkeit, KI-Ausgaben zu verwalten und gleichzeitig Teams zu ermöglichen, mühelos zu wachsen und sich anzupassen. Diese Pläne basieren auf Strategien wie Kostenverfolgung und modularer Skalierbarkeit, um sicherzustellen, dass Ressourcen effizient genutzt werden.
With pay-as-you-go pricing, you’re only charged for the tokens and compute time you actually use. Real-time dashboards provide insights into token consumption, latencies, and outcomes, helping to pinpoint inefficiencies and eliminate unnecessary spending. When combined with scale-to-zero capabilities, this model becomes even more effective - idle inference endpoints automatically shut down, so you’re not paying for unused GPU resources.
For tasks that aren’t time-sensitive, such as exploratory data analysis or offline model training, spot pricing offers a lower-cost alternative to on-demand rates. These savings add up, especially when paired with tools that track usage and performance in real time, allowing teams to fine-tune their compute needs and stay within budget.
Elastic compute ensures that your workflows can adapt to changing demands without manual adjustments. Features like autoscaling node pools and serverless architectures handle fluctuating workloads seamlessly, so there’s no need to overprovision resources for peak usage. By separating model artifacts from application code and using cloud storage, pods can start up almost instantly, making scaling operations faster and more efficient.
This approach is particularly valuable when transitioning from pilot projects to full-scale production. As the global MLOps market grows - expected to rise from $1.58 billion in 2024 to $2.33 billion by 2025 - organizations need scalable systems that won’t require constant rebuilding. Pay-as-you-go plans align costs with actual usage, making it easier to expand models, users, or teams without driving up expenses.
Pay-as-you-go-Pläne arbeiten Hand in Hand mit fortschrittlichen Team-Tools, um das Kostenmanagement und die betrieblichen Arbeitsabläufe zu optimieren. Moderne Tools integrieren Governance, Audit-Trails und Sicherheitsfunktionen wie Single Sign-On (SSO) und rollenbasierte Zugriffskontrolle (RBAC) direkt in die Orchestrierungsebene. Diese Fähigkeiten sind für die Erfüllung von Compliance-Anforderungen wie SOC 2 oder ISO 27001 unerlässlich.
Plattformen, die Unterstützung für OpenAI-kompatible APIs bieten, ermöglichen es Teams, zwischen LLM-Anbietern oder -Modellen zu wechseln, ohne ihre Arbeitsabläufe zu überarbeiten, und sorgen so für Flexibilität, wenn neue Technologien aufkommen. Verwaltete Umgebungen verbessern den Teambetrieb weiter, indem sie Funktionen wie Berechtigungen, SLAs, zentralisierte Metadatenverfolgung und Autorisierungskontrollen integrieren. Diese Systeme passen sich nicht nur Ihrem Unternehmen an, sondern gewährleisten auch die Transparenz und Kontrolle, die zur Einhaltung gesetzlicher Standards erforderlich sind. Sie stellen sicher, dass jedes Teammitglied den richtigen Zugriff hat und jede Aktion zur Prüfung protokolliert wird.
Der Aufbau effektiver KI-Workflows erfordert leistungsstarke Modelle in Kombination mit einem strukturierten und skalierbaren Ansatz. Die sieben zuvor besprochenen Praktiken tragen dazu bei, unzusammenhängende KI-Initiativen in optimierte, unternehmenstaugliche Prozesse umzuwandeln. Durch die Integration verschiedener LLMs, eine kontinuierliche Kostenüberwachung und die Nutzung modularer Designs können Sie Engpässe beseitigen und Arbeitsabläufe erstellen, die sich Ihren Anforderungen anpassen. Beginnend mit der Governance stellt sicher, dass jede KI-Entscheidung sowohl nachvollziehbar als auch konform ist, während von der Community gesteuerte Eingabeaufforderungen und automatisierte Testzyklen die Entwicklung beschleunigen, ohne die Qualität zu beeinträchtigen. Diese Strategien bilden das Rückgrat eines effizienten und zuverlässigen KI-Betriebs.
Wie bereits erwähnt, können diese Methoden die Effizienz in Arbeitsabläufen wie Onboarding und Vorfallmanagement um 20 bis 50 % steigern. Die Kostenverfolgung in Echtzeit, gepaart mit Pay-as-you-go-Modellen, sorgt dafür, dass die Ausgaben an der Nutzung ausgerichtet sind, Budgetüberschreitungen vermieden werden und gleichzeitig eine nahtlose Skalierung unterstützt wird. Durch die Integration von Automatisierungs- und Feedbackschleifen können sich KI-Systeme selbst optimieren, Anomalien erkennen, Verbesserungen vorschlagen und komplexe Aufgaben autonom verwalten.
Der Trend hin zu integrierter Governance und adaptiven Architekturen unterstreicht, wie wichtig es ist, Arbeitsabläufe auf einer soliden Grundlage aufzubauen. Standardisierte Tools, klare Komponentengrenzen und detaillierte Ablaufverfolgungen stellen sicher, dass Ihre Systeme flexibel bleiben, wenn neue Modelle und Funktionen auftauchen. Durch die Konzentration auf skalierbare, wiederholbare Prozesse können Sie ohne ständige Überholungen von Pilotprojekten zur Serienproduktion übergehen.
Zusammen verwandeln diese Strategien fragmentierte Experimente in effiziente, nachvollziehbare und kostenbewusste Arbeitsabläufe. Sind Sie bereit, die Kontrolle über Ihre KI-Workflows zu übernehmen? Mit Prompts.ai können Sie Ihre Modelle sichern, Kosten verwalten und mühelos skalieren. Greifen Sie auf über 35 Top-Modelle zu, nutzen Sie integrierte FinOps-Kontrollen und implementieren Sie Governance auf Unternehmensniveau – alles über eine einzige Schnittstelle. Prompts.ai eliminiert die Tool-Überflutung, sorgt für Compliance und ermöglicht es Ihrem Team, sich auf Innovationen zu konzentrieren, wodurch das KI-Chaos in einen optimierten, ROI-gesteuerten Betrieb verwandelt wird.
Um das am besten geeignete Large Language Model (LLM) auszuwählen, müssen Sie zunächst Ihre spezifischen Anforderungen klar identifizieren – sei es für das Schreiben, Codieren, den Kundensupport oder eine andere Anwendung. Bewerten Sie Modelle mithilfe eines strukturierten Ansatzes, der Faktoren wie Leistung, Kosten und Datenschutz berücksichtigt. Priorisieren Sie für Aufgaben mit minimalem Risiko Modelle, die schneller und budgetschonender sind. Andererseits erfordern anspruchsvolle Aufgaben Modelle, die zuverlässiger sind und eine ordnungsgemäße Überwachung umfassen. Benchmarking ist ein entscheidender Schritt, um sicherzustellen, dass das ausgewählte Modell sowohl Ihren Aufgabenanforderungen als auch Ihren Betriebszielen entspricht.
Um die KI-Kosten unter Kontrolle zu halten, ist eine Überwachung unerlässlich Token-Nutzung wie es passiert. Dies beinhaltet die Verfolgung von Anfragen, Eingabeaufforderungen und Modellaufrufen. Indem Sie den Überblick über diese Kennzahlen behalten, können Sie Ineffizienzen erkennen und Anpassungen vornehmen, um die Ressourcennutzung zu optimieren und so ein Gleichgewicht zwischen Kosten und Leistung aufrechtzuerhalten.
Um der Modellabweichung immer einen Schritt voraus zu sein, richten Sie automatisierte Überwachungssysteme ein, die Leistungskennzahlen und Datenqualität in Echtzeit genau überwachen. Diese Tools können Verschiebungen wie Konzeptdrift, Kovariatenverschiebung oder Labeldrift erkennen, indem sie Änderungen in der Datenverteilung und Vorhersagegenauigkeit untersuchen. Wenn eine Abweichung erkannt wird, können vordefinierte Neuschulungsauslöser eingreifen, um Ihre Modelle schnell zu aktualisieren und so eine konsistente Validierung und eine reibungslose Integration in Ihre MLOps-Prozesse sicherzustellen.



















