ادفع حسب الاستخدام - AI Model Orchestration and Workflows Platform

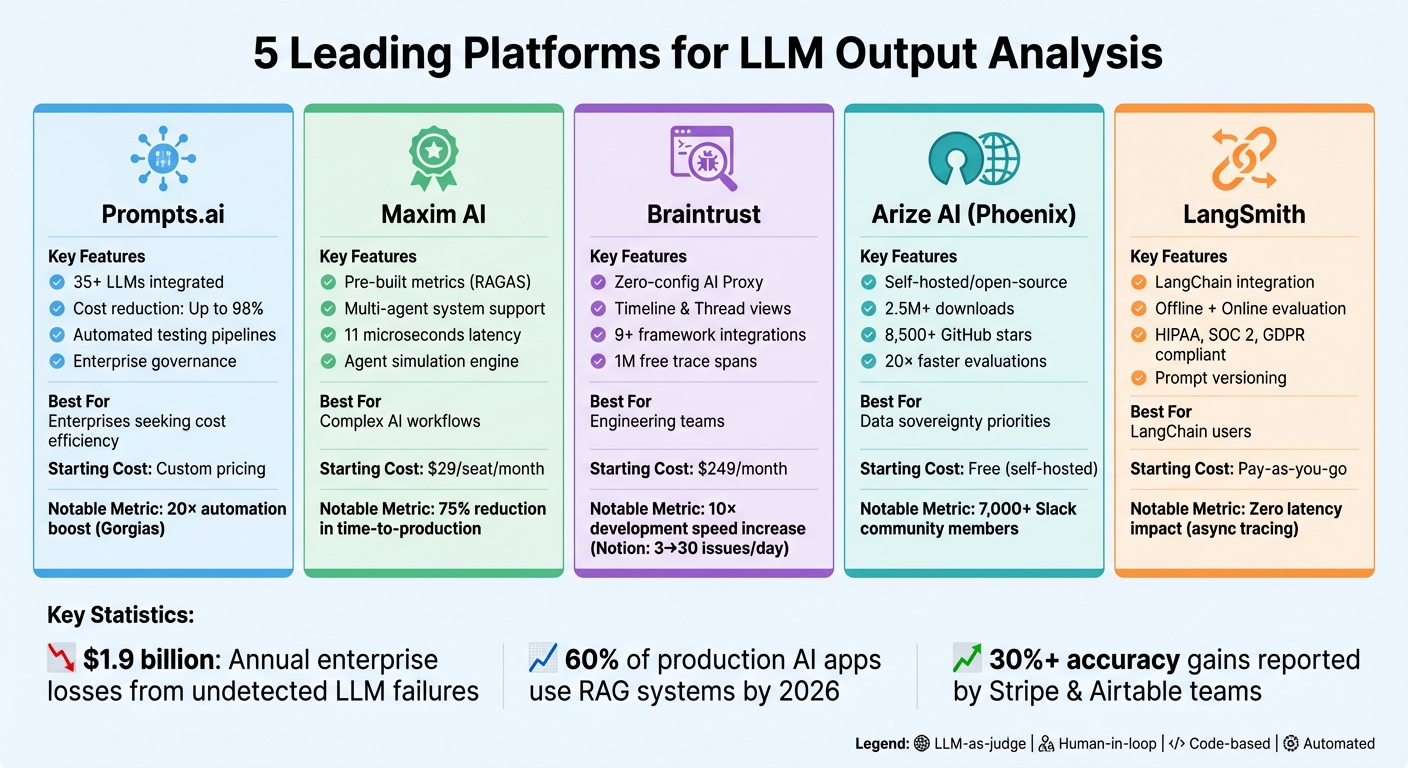
تعد نماذج اللغات الكبيرة (LLMs) قوية ولكن لا يمكن التنبؤ بها، وغالبًا ما تنتج مخرجات غير متسقة أو مكلفة. ولمواجهة هذه التحديات، تعتمد المؤسسات على أدوات متخصصة للتقييم والمراقبة وإدارة التكاليف. يقدم هذا المقال خمس منصات التي تبسط تحليل مخرجات LLM:
تتناول كل منصة جوانب فريدة من سير عمل LLM، بدءًا من تحسين الدقة وحتى خفض التكاليف وضمان الامتثال.
| منصة | الميزات الرئيسية | أفضل ل | تكلفة البداية |
|---|---|---|---|
| Prompts.ai | الوصول المركزي إلى LLM وأدوات FinOps الموفرة للتكلفة | تسعى الشركات إلى تحقيق كفاءة التكلفة | التسعير المخصص |
| مكسيم آي | مقاييس معدة مسبقًا، ودعم نظام متعدد الوكلاء | تدير الفرق مسارات عمل الذكاء الاصطناعي المعقدة | 29 دولارًا/المقعد/الشهر |
| الثقة بالعقل | أدوات تصحيح الأخطاء واختبار المحادثة متعدد المنعطفات | الفرق الهندسية | 249 دولارًا شهريًا |
| أريزي منظمة العفو الدولية | مصدر مفتوح، تتبع تفصيلي، فحوصات الهلوسة | المنظمات التي تعطي الأولوية للتحكم في البيانات | مجاني (مستضاف ذاتيًا) |
| لانج سميث | تكامل LangChain، الإصدار الفوري | مستخدمي لانج تشين | الدفع عند الاستخدام |
تعمل هذه المنصات على تبسيط إدارة LLM، مما يضمن عمليات ذكاء اصطناعي قابلة للتطوير وموثوقة وفعالة من حيث التكلفة.
__XLATE_5__
Prompts.ai brings together 35+ top-tier LLMs - including GPT‑5, Claude, LLaMA, and Gemini - into one unified platform designed for enterprise-level prompt engineering and detailed output analysis. It simplifies evaluation with automated testing pipelines.
يتميز Prompts.ai بخطوط تقييم قادرة على إجراء أكثر من 20 اختبارًا على مجموعات البيانات السريعة. يتضمن ذلك طرقًا مثل تأكيدات LLM (باستخدام الذكاء الاصطناعي لتصنيف المخرجات)، وعمليات التحقق من التشابه الدلالي من خلال تشابه جيب التمام، وتقييمات المطابقة التامة، ومطابقة الأنماط المستندة إلى التعبير العادي. يمكن للفرق أيضًا دمج التقييمات البشرية من خلال لوحة معلومات سهلة الاستخدام، مما يسمح لخبراء المجال بتقييم المخرجات يدويًا كجزء من التعلم المعزز من الملاحظات البشرية.
For instance, Gorgias, a customer support platform, used Prompts.ai to scale its AI-powered helpdesk to support millions of shoppers. This led to a 20× boost in automation. Their ML engineers and support teams run daily regression tests on backtest datasets to catch potential issues before deployment.
تضمن إمكانات الاختبار الصارمة هذه التكامل السلس في سير العمل الحالي.
Prompts.ai’s evaluation pipelines seamlessly integrate with CI/CD workflows and enable backtesting against historical production data. The platform supports connections through external HTTP endpoints, custom Python/JavaScript scripts, and Model Context Protocol (MCP) actions.
استفاد تطبيق Speak، وهو تطبيق لتعلم اللغة، من ميزات الأتمتة هذه لتكثيف أشهر من تطوير المناهج الدراسية في أسبوع واحد فقط. وسمحت لهم هذه الكفاءة بإطلاق ميزات تعتمد على الذكاء الاصطناعي في 10 أسواق جديدة في نفس الوقت.
يساعد Prompts.ai أيضًا الفرق على تحسين التكاليف من خلال تقديم طرق عرض مقارنة النماذج جنبًا إلى جنب. تتيح هذه المقارنات للمستخدمين تقييم المفاضلات بين تكاليف واجهة برمجة التطبيقات (API)، وزمن الوصول، ونقاط الجودة. يمكن للفرق تلخيص المخرجات أو استخدام نماذج أصغر وأسرع للمهام المتوسطة لتقليل استخدام الرمز المميز. تستخدم NoRedInk، التي تخدم 60% من المناطق التعليمية في الولايات المتحدة، هذه الميزات الموفرة للتكلفة لتقديم تعليقات تم إنشاؤها بواسطة الذكاء الاصطناعي على أكثر من مليون درجة طالب، كل ذلك مع الحفاظ على الجودة على مستوى المعلم.
تعمل Prompts.ai على تعزيز التعاون من خلال تزويد جميع أصحاب المصلحة بالأدوات اللازمة لتحسين مخرجات LLM. يتيح المحرر المرئي بدون تعليمات برمجية للمستخدمين غير التقنيين تحرير المطالبات واختبارها دون الاعتماد على المهندسين. يضمن السجل الفوري المركزي إدارة الإصدار بكفاءة.
على سبيل المثال، وفرت شركة ParentLab أكثر من 400 ساعة هندسية في ستة أشهر فقط من خلال تمكين خبراء المجال غير التقنيين من إدارة 700 مراجعة سريعة.
__XLATE_12____XLATE_13__
تقوم المنصة أيضًا بجمع تقييمات المستخدمين وترجمتها إلى درجات أداء، مما يؤدي إلى إنشاء حلقة تعليقات مستمرة لتحسين جودة المخرجات عبر جميع النماذج المتكاملة.
يوفر Maxim AI أدوات اختبار ومراقبة متعمقة، ويمزج التقييمات التي تعتمد على الآلة مع التعليقات البشرية لدعم الفرق التي تدير مسارات عمل الذكاء الاصطناعي المعقدة. تم تصميم ميزاته لضمان إجراء تقييمات شاملة، والتي تعتبر ضرورية للحفاظ على أداء قوي في LLM.
يستخدم Maxim AI إطار تقييم قوي يتضمن الاختبارات الحتمية والأساليب الإحصائية وأدوات الحكم الآلية. ال متجر المثمن تقدم مقاييس معدة مسبقًا مثل RAGAS، والمصممة خصيصًا لأنظمة الجيل المعزز للاسترجاع - وهي المكونات الرئيسية في حوالي 60% من تطبيقات الذكاء الاصطناعي للإنتاج بحلول عام 2026. بالإضافة إلى ذلك، مقاييس مستوى العقدة help identify failures in retrieval and generation processes. The platform’s محاكاة الوكيل يتيح المحرك اختبار المحادثة متعدد المنعطفات وإنشاء شخصية المستخدم لتقييمات ما قبل النشر. أبلغت شركات مثل Clinc وMindtickle عن انخفاض بنسبة 75% في الوقت اللازم للإنتاج من خلال اعتماد معايير الجودة هذه.
Maxim AI’s evaluation tools integrate effortlessly with today’s development environments. It supports SDKs in Python, TypeScript, Java, and Go, while offering compatibility with platforms like LangChain, LangGraph, Crew AI, OpenAI, Anthropic, Mistral, and AWS Bedrock. The platform also adheres to فتح القياس عن بعد معايير التتبع الموزع والاتصال بأدوات مثل Slack وPagerDuty للتنبيهات في الوقت الفعلي. يستفيد مستخدمو المؤسسات من خيارات النشر التي تشمل الاستضافة السحابية وIn-VPC، وكلها تلبي متطلبات الامتثال SOC2 وHIPAA وGDPR.
ال بوابة بيفروست LLM يستخدم التخزين المؤقت الدلالي لتقليل النفقات، مع مراقبة استخدام الرمز المميز وتكاليف واجهة برمجة التطبيقات لتحديد ومعالجة سير العمل المكلف. وهذا يضمن كفاءة العمليات مثل موازين الإنتاج.
Maxim AI’s واجهة مستخدم بدون كود يُمكّن مديري المنتجات والمصممين من تجربة المطالبات وإجراء التقييمات بشكل مستقل. شاركت كيلي مالوني، قائدة المنتج في Rise Science:
__XLATE_29__
يتضمن النظام الأساسي أيضًا قوائم انتظار التعليقات التوضيحية للمراجعات البشرية، ونظام إدارة المحتوى الفوري (CMS) المركزي مع التحكم في الإصدار، وRBAC مع دعم SAML/SSO. حققت الفرق التي تستفيد من أدوات التعاون هذه زيادة في سرعة الشحن بمقدار خمسة أضعاف، مما أدى إلى تبسيط التكرار وتسريع عمليات طرح الإنتاج.
يجمع Braintrust بين التجارب غير المتصلة بالإنترنت والتسجيل عبر الإنترنت لمنح الفرق رؤية كاملة لأداء LLM بدءًا من التطوير وحتى النشر.
يوفر Braintrust طرقًا متعددة لتقييم جودة المخرجات على مقياس من 0 إلى 1. يمكن للفرق استخدام أدوات تسجيل النقاط الآلية لمهام مثل التحقق من الوقائع والتشابه، أو الاعتماد على تقييمات LLM كقاض، أو تنفيذ منطق كود مخصص مصمم خصيصًا لتلبية احتياجاتهم الخاصة. تتضمن المنصة طرق عرض الجدول الزمني مع مخططات جانت لتحديد الاختناقات، مشاهدات الموضوع لتصحيح أخطاء المحادثات متعددة المنعطفات، وتصورات التتبع المستندة إلى اللغة الطبيعية والتي يتم عرضها كمكونات React في وضع الحماية. كما أنه يدعم إجراء تجارب متعددة لكل إدخال، مما يساعد الفرق على قياس التباين والحفاظ على الاتساق.
يتكامل Braintrust بسلاسة مع أطر عمل الذكاء الاصطناعي الرائدة، ويقدم دعمًا أصليًا لـ 9+ الأطر الرئيسية، مثل OpenTelemetry وVercel AI SDK وOpenAI Agent SDK وInstructor وLangChain وLangGraph وGoogle ADK وMastra وPydantic AI. ويستخدم "التفاف" نهج التكامل - تشمل الأمثلة التفافAISDK لـ Vercel AI SDK (يغطي الإصدارات v3 إلى v6 beta) و Wrap_openai للمدرس. تلتزم المنصة الاصطلاحات الدلالية OpenTelemetry GenAI، وتعيين التفاصيل تلقائيًا مثل استخدام الرمز المميز ومعرفات النماذج لحقول Braintrust. إنه يعمل بسلاسة مع مقدمي خدمات LLM الرئيسيين، بما في ذلك OpenAI وAnthropic وGoogle Gemini. يمكن للمطورين أيضًا استخدام تقييم () وظيفة أو CLI مع --يشاهد علامة لإعادة تشغيل التقييمات تلقائيًا عندما يتم تحديث الملفات أثناء التطوير.
تتخطى Braintrust التقييم من خلال تعزيز تعاون الفريق باستخدام الأدوات المدمجة. إنه تزامن ثنائي الاتجاه يضمن أن مديري المنتجات والمهندسين يمكنهم العمل على المطالبات بالتبادل بين التعليمات البرمجية وواجهة المستخدم. ال ملعب يوفر مساحة بدون تعليمات برمجية حيث يمكن للفرق اختبار المطالبات ومقارنة النماذج جنبًا إلى جنب ومشاركة التكوينات للتكرار السريع. تسمح أدوات التعليقات التوضيحية المخصصة للفرق بتقديم تعليقات بشرية في الحلقة، وإضافة تسميات أو تصحيحات مباشرة إلى التتبعات ومخرجات النموذج. يمكن دعوة المعلقين الخارجيين لتقييم الجودة عبر إصدارات مختلفة من النماذج، في حين أن تراكمات التقييم المشتركة تعمل على مركزية مجموعات البيانات ونماذج التقييم، مما يلغي الحاجة إلى التتبع اليدوي لجداول البيانات.
Arize AI's Phoenix عبارة عن منصة مفتوحة المصدر مصممة لمنح الفرق تحكمًا شاملاً في تقييم نماذج اللغات الكبيرة (LLMs). تم تصميم Phoenix باستخدام OpenTelemetry في جوهره، وقد استحوذ على الاهتمام بأكثر من 2.5 مليون عملية تنزيل وأكثر من 8500 نجم على GitHub. وهو يوفر تتبعًا تفصيليًا لتتبع كل خطوة من خطوات سير عمل LLM، مما يسهل تحديد مكان ظهور المشكلات.
توظف شركة فينيكس ماجستير في القانون كقاض النهج، باستخدام النماذج الأساسية من OpenAI وAnthropic وGemini لتقييم تطبيقات LLM الأخرى لعوامل مثل الملاءمة والسمية والأداء العام. يأتي مزودًا بمقيمين تم إعدادهم مسبقًا للمهام الشائعة مثل إنشاء الاسترجاع المعزز (RAG) واستدعاء الوظائف. الميزة البارزة هي القدرة على التفسير، حيث توفر نماذج التقييم سببًا واضحًا وراء نتائجها، مما يساعد المطورين على فهم المنطق وراء كل تقييم. تشتمل الأدوات الإضافية على فحوصات حتمية قائمة على التعليمات البرمجية، والتعليقات التوضيحية البشرية مباشرة داخل الواجهة، و تجميع مجموعة البيانات يستخدم التضمينات لتجميع الأسئلة والإجابات المتشابهة بشكل مرئي. يساعد هذا التجميع على عزل المناطق التي يكون أداء النماذج فيها ضعيفًا.
__XLATE_63__
تتكامل أدوات التقييم هذه بسلاسة مع النظام البيئي التطويري الأوسع للمنصة.
يدعم Phoenix الأجهزة التلقائية لأطر العمل الشائعة مثل LlamaIndex وLangChain وDSPy وMastra وVercel AI SDK. وهو يعمل مع Python وTypeScript وJava، ويضمن تصميمه الأصلي OpenTelemetry التوافق مع أدوات المراقبة الحالية دون تقييد المستخدمين ببائعين محددين. يمكن للفرق أيضًا دمج التقييمات من مكتبات الجهات الخارجية مثل Ragas، أو Deepeval، أو Cleanlab، مما يوفر المرونة عبر سير العمل الخاص بهم.
تم تصميم Phoenix لتحقيق الكفاءة والتوصيل ما يصل إلى 20x عمليات تقييم أسرع من خلال التزامن والدفعات. توفر ساحة اللعب الفورية الخاصة بها بيئة اختبار حيث يمكن للفرق تحسين المطالبات ومقارنة متغيرات النماذج جنبًا إلى جنب قبل النشر، مما يقلل من مخاطر أخطاء الإنتاج الباهظة الثمن.
وباعتبارها منصة مفتوحة المصدر بالكامل وذاتية الاستضافة، تضمن شركة Phoenix احتفاظ الفرق بالتحكم الكامل في بياناتهم. ميزات مثل قوائم انتظار التعليقات التوضيحية البشرية السماح بإضافة تسميات الحقيقة الأساسية مباشرة إلى الآثار، مما يعزز التعاون بشكل أفضل. ال المحور الفوري يدير الإصدار السريع والتخزين والنشر عبر البيئات، في حين أن سبان الدردشة تمكن الأداة الفرق من تقييم ومناقشة قطاعات سير عمل محددة للكشف عن مشكلات الأداء. مع مجتمع Slack الذي يضم أكثر من 7000 عضو، يمكن للمستخدمين الوصول إلى الشبكة لاستكشاف الأخطاء وإصلاحها ومشاركة الأفكار.
__XLATE_76__
LangSmith عبارة عن منصة متعددة الاستخدامات مصممة للعمل بسلاسة مع LangChain أو بدونها، مما يجعلها قابلة للتكيف مع أي مكدس LLM. فهو يتصل بسهولة بأدوات مثل OpenAI وAnthropic وCrewAI وVercel AI SDK وPydantic AI، مما يوفر المرونة للفرق التي تستخدم بالفعل أطر عمل محددة. تلبي المنصة معايير الامتثال مثل HIPAA، وSOC 2 Type 2، وGDPR، وتستخدم عملية غير متزامنة لإرسال التتبعات، مما يضمن عدم وجود زمن انتقال إضافي للمستخدمين النهائيين.
عروض لانج سميث وضعين للتقييم لتناسب الاحتياجات المختلفة: التقييم دون الاتصال بالإنترنت لاختبار مجموعات البيانات المنسقة أثناء التطوير والتقييم عبر الإنترنت لمراقبة حركة الإنتاج المباشر. وهو يدعم أربعة أنواع من المقيمين:
تتضمن المنصة أدوات تحليل متقدمة مثل عرض الفرق، الذي يسلط الضوء على الاختلافات بين مخرجات النموذج والنصوص المرجعية، والمقارنات جنبًا إلى جنب لقياس الأداء. كما يوفر تجميع البيانات الوصفية، مما يتيح تحليل المقاييس مثل الدقة أو التكلفة حسب فئات مثل مجال الموضوع أو نوع المستخدم. يتكامل LangSmith مع المصدر المفتوح مفتوح الحزمة، التي تقدم مقيمين معدين مسبقًا لتقييم الصحة والإيجاز.
تسهل هذه الميزات دمج LangSmith في مهام سير العمل وأدوات التطوير الحالية.
يقوم LangSmith بتبسيط عملية التتبع باستخدام أداة @ يمكن تتبعها مصمم الديكور أو أغلفة العميل التي تلتقط المدخلات والمخرجات تلقائيًا. وهو يدعم التكامل مع Python وTypeScript/JavaScript SDKs وREST API وأطر الاختبار مثل pytest وVitest وJest، مما يجعل من السهل تضمين التقييمات في مسارات CI/CD. بالإضافة إلى ذلك، يسمح تكامل OpenTelemetry للفرق بإرسال آثار من خطوط أنابيب المراقبة الحالية مباشرةً إلى LangSmith.
يعزز LangSmith تعاون الفريق من خلال أدوات الملاحظات والتعليقات التوضيحية البديهية. قوائم انتظار التعليقات التوضيحية تمكين التوجيه التلقائي لعمليات تشغيل محددة للخبراء المتخصصين للمراجعة اليدوية والتسجيل بناءً على معايير مخصصة. ال المحور الفوري بمثابة مساحة مركزية للفرق لتكرار المطالبات وإصدارها ومشاركتها، مع استكمال ميزات تتبع التغيير والتراجع للحفاظ على الاتساق طوال عملية التطوير. تتيح إمكانات التعليقات التوضيحية المضمنة لأعضاء الفريق تحديد المشكلات أو تقديم تعليقات مستهدفة حول جودة الاستجابة، مما يؤدي إلى تحسين دقة التقييم وكفاءة سير العمل.
توفر المنصة أيضًا إدارة مفصلة للمستخدم وعزل عبء العمل، مما يضمن التعاون السلس بين الفرق. يمكن للمستخدمين التسجيل مجانًا على smith.langchain.com - دون الحاجة إلى بطاقة ائتمان. بالنسبة للاستخدام الإنتاجي، تعمل LangSmith على أساس الدفع أولاً بأول، مع توفر خطط المؤسسة للاستضافة الذاتية على مجموعات Kubernetes عبر AWS أو GCP أو Azure.
عند تقييم الأنظمة الأساسية لتقييم LLM، من الضروري مراعاة التوافق الفني والتكلفة وطرق التقييم. وفيما يلي نظرة فاحصة على الخيارات:
Prompts.ai يجمع أكثر من 35 نموذجًا رائدًا تحت واجهة واحدة آمنة، ويقدم عناصر تحكم FinOps التي يمكنها تقليل تكاليف برامج الذكاء الاصطناعي بنسبة تصل إلى 98%. الثقة بالعقل يبسط عملية الإعداد باستخدام وكيل AI بدون تكوين، حيث يلتقط السجلات عبر عنوان URL أساسي واحد. يتضمن مليون امتداد تتبع مجاني، مع خطط مدفوعة تبدأ من 249 دولارًا شهريًا. مكسيم آي يتكامل بسلاسة مع مجموعات إمكانية المراقبة الحالية، مع التركيز على تسجيل الجودة عبر التتبع الكامل. يقدم خطة مجانية لما يصل إلى 10000 سجل شهريًا وخطط مدفوعة تبدأ من 29 دولارًا لكل مقعد / شهر. أريزي فينيكس يدعم الاستضافة الذاتية لخصوصية البيانات، والتكامل مع أدوات مثل RAGAS وGiskard لإجراء تحليل متري أعمق. لانج سميث تم تصميمه خصيصًا لمستخدمي LangChain، مما يوفر إمكانية مراقبة متقدمة، على الرغم من اختلاف أسعار دعم المؤسسات. والجدير بالذكر أن Notion حسنت سرعة تطورها بمقدار عشرة أضعاف مع Braintrust، حيث زادت من حل 3 مشكلات يوميًا إلى 30.
يعمل النهج الفريد لكل منصة على تبسيط عملية اتخاذ القرار بناءً على احتياجات التقييم المحددة الخاصة بك. وإليك كيفية المقارنة بينهما من حيث طرق التقييم والتكامل والنشر:
يلعب تعقيد التكامل أيضًا دورًا رئيسيًا. يعد إعداد Braintrust المستند إلى الوكيل أمرًا مباشرًا - ما عليك سوى تحديث عنوان URL الأساسي لواجهة برمجة التطبيقات (API) الخاصة بك. يتكامل Maxim AI مع أدوات المراقبة الحالية، بينما يلبي تكامل LangSmith الوثيق مع LangChain احتياجات إمكانية المراقبة المتخصصة. تتميز Arize Phoenix بالمنظمات التي تعطي الأولوية لسيادة البيانات، وتقدم حلاً مفتوح المصدر مستضافًا ذاتيًا. وفي الوقت نفسه، توفر Prompts.ai ضوابط حوكمة على مستوى المؤسسات ومسارات تدقيق كاملة للتشغيل الآمن.
__XLATE_111__
للحصول على رؤى سريعة، تعمل عمليات النشر المستندة إلى الوكيل والتكامل العميق على تبسيط العملية. سيجد مستخدمو LangChain أن LangSmith مناسب تمامًا، في حين أن المؤسسات التي تدير البيانات الحساسة قد تميل نحو الحلول مفتوحة المصدر مثل Arize Phoenix أو Prompts.ai للحصول على إمكانات قوية للحوكمة والتدقيق.
بناءً على التقييمات المقدمة، توفر كل منصة مزايا مميزة لتحسين تحليل مخرجات LLM. Prompts.ai يوفر للمؤسسات وصولاً مركزيًا إلى النماذج الرائدة، مقترنة بضوابط FinOps التي يمكنها تقليل تكاليف الذكاء الاصطناعي بنسبة تصل إلى 98%، مع ضمان قدرات قوية للحوكمة والتدقيق. الثقة بالعقل تم تصميمه خصيصًا للفرق الهندسية سريعة الخطى، حيث أبلغت شركات مثل Notion عن زيادة في سرعة التطوير بمقدار 10 أضعاف - مما أدى إلى زيادة حل المشكلات من 3 إلى 30 يوميًا. وبالمثل، لاحظت الفرق في Stripe وAirtable مكاسب دقة تزيد عن 30% خلال أسابيع من اعتماد المنصة.
بالنسبة لأولئك المندمجين بعمق في نظام LangChain البيئي، لانج سميث يوفر تكاملًا سهلاً وخيارات نماذج أولية سريعة. مكسيم آي تلبي احتياجات الفرق التي تركز على إدارة أنظمة معقدة متعددة الوكلاء، وتقدم أدوات تسجيل دقيقة وبوابة ذات زمن وصول منخفض تقدم 11 ميكروثانية فقط من الحمل بحجم 5000 طلب في الثانية. في أثناء، أريزي فينيكس يعد مثاليًا للمؤسسات التي تعطي الأولوية لسيادة البيانات، وتقدم حلاً مستضافًا ذاتيًا ومفتوح المصدر يتناسب بسلاسة مع أنظمة المراقبة الحالية.
تتناول كل منصة التحديات الحاسمة في أداء LLM وإدارة التكاليف. مع مواجهة الشركات لخسائر محتملة 1.9 مليار دولار سنويا نظرًا لفشل LLM غير المكتشف في الإنتاج، أصبحت الحاجة إلى تجاوز التقييمات الذاتية إلى مقاييس قابلة للقياس تعتمد على البيانات ضرورية لضمان الموثوقية والكفاءة.
تعمل هذه الأدوات على رفع مستوى تطوير LLM إلى تخصص هندسي منظم. سواء كان تركيزك ينصب على التعامل مع تريليونات الأحداث شهريًا، أو تبسيط التعاون عبر الفرق، أو الحفاظ على التحكم في البنية التحتية المستضافة ذاتيًا، فإن اختيار النظام الأساسي المناسب يضمن أن سير عمل LLM الخاص بك يحقق الموثوقية والجودة وفعالية التكلفة المطلوبة لتحقيق أهدافك.
تم تصميم هذه المنصات لمساعدة المؤسسات على خفض نفقات الذكاء الاصطناعي من خلال تقديم أدوات لمراقبة وضبط استخدام نماذج اللغات الكبيرة (LLMs). على سبيل المثال، تسمح حلول مثل Prompts.ai للمستخدمين بتتبع استخدام الرمز المميز في الوقت الفعلي، مما يسهل اكتشاف وتقليل استهلاك الرمز المميز غير الضروري. ويساعد ذلك على تجنب الإنفاق الزائد على استدعاءات واجهة برمجة التطبيقات (API) المفرطة، مما يؤدي إلى إدارة أفضل للتكلفة.
وبعيدًا عن التحكم في التكاليف، توفر هذه المنصات أيضًا رؤى قيمة حول الأداء وجودة المخرجات. يمكنهم المساعدة في اكتشاف ومنع مشكلات مثل الهلوسة أو الأخطاء، والتي قد تؤدي إلى إعادة صياغة مكلفة. ومن خلال تحليل اتجاهات الاستخدام وتحديد أوجه القصور، يمكن للمؤسسات تبسيط سير العمل وخفض تكاليف التشغيل وضمان نتائج متسقة وعالية الجودة. كل هذا يدعم القرارات الأكثر ذكاءً والمعتمدة على البيانات لإدارة ميزانيات الذكاء الاصطناعي بشكل فعال.
توفر منصات LLM طرقًا مختلفة للاتصال بسلاسة بالأدوات وسير العمل، بما يلبي الاحتياجات المختلفة. تدعم العديد من الأنظمة الأساسية التكامل الأصلي من خلال حزم SDK مثل Python وJavaScript، جنبًا إلى جنب مع أطر عمل مثل LangChain وLangServe. وهذا يجعل دمج LLMs في التطبيقات المخصصة أمرًا سهلاً وفعالاً. بالنسبة للمراقبة، غالبًا ما تدعم الأنظمة الأساسية المعايير المفتوحة مثل OpenTelemetry، مما يضمن التوافق مع البنية التحتية الحالية.
تتكامل بعض الأنظمة الأساسية أيضًا مع أدوات CI/CD مثل GitHub Actions وJenkins، مما يبسط عمليات الاختبار والنشر. بالنسبة للمؤسسات التي تعطي الأولوية للتحكم في بيئتها، تتوفر خيارات الاستضافة الذاتية، مما يسمح بالتخصيص مع الحفاظ على أمان البيانات. تتيح ميزات التكامل هذه للمستخدمين تعزيز الكفاءة ومراقبة الأداء بفعالية وتنفيذ LLMs بشكل آمن ضمن عملياتهم.
بالنسبة لأولئك الذين يضعون علاوة على خصوصية البيانات والتحكم فيها, OnPrem.LLM يقدم حلا ممتازا. تم تصميم هذا النظام الأساسي خصيصًا للمهام الحساسة للخصوصية، وهو يسمح لنماذج اللغات الكبيرة (LLMs) بالتعامل مع البيانات السرية أو المقيدة بشكل آمن في الإعدادات غير المتصلة بالإنترنت. من خلال تمكين التنفيذ المحلي بالكامل، فإنه يقلل بشكل كبير من فرص التعرض للبيانات، مع تقديم أيضًا تكامل سحابي اختياري للإعدادات المختلطة عند الضرورة.
بفضل واجهته البديهية التي لا تحتوي على تعليمات برمجية، يضمن OnPrem.LLM إمكانية الوصول للمستخدمين الذين ليس لديهم خبرة فنية، كل ذلك مع الحفاظ على الإشراف الكامل على إدارة البيانات. وهذا يجعله خيارًا مثاليًا للمؤسسات في الصناعات المنظمة أو الحساسة حيث تكون حماية المعلومات أولوية قصوى.



















